| | |
```
In this scenario, Task 3 in the "Code Review" column requires human intervention. This is similar to how HITL works in AI workflows, where certain tasks need human input or validation before proceeding.
### How HITL Works in KaibanJS
1. **Task Creation**: Tasks are created and can be flagged to require human validation.
2. **AI Processing**: AI agents work on tasks, moving them through different states (like "To Do" to "In Progress").
3. **Human Intervention Points**:
- Tasks enter 'AWAITING_VALIDATION' state when they need human review.
- Humans can provide feedback on tasks in 'BLOCKED', 'AWAITING_VALIDATION', or even 'DONE' states.
4. **Feedback or Validation**:
- Humans can validate (approve) a task or provide feedback for revisions.
- Feedback can be given to guide the AI's next steps or to request changes.
5. **Feedback Processing**:
- If feedback is provided, the task moves to 'REVISE' state.
- The AI agent then addresses the feedback, potentially moving the task back to 'DOING'.
6. **Completion**: Once validated, tasks move to the 'DONE' state.
This process ensures that human expertise is incorporated at crucial points, improving the overall quality and reliability of the AI-driven workflow.
### This HITL workflow can be easily implemented using KaibanJS.
The library provides methods and status to manage the entire process programmatically:
- Methods: `validateTask()`, `provideFeedback()`, `getTasksByStatus()`
- Task Statuses: TODO, DOING, BLOCKED, REVISE, AWAITING_VALIDATION, VALIDATED, DONE
- Workflow Status: INITIAL, RUNNING, BLOCKED, FINISHED
- Feedback History: Each task contains a `feedbackHistory` array, with entries consisting of:
- `content`: The human input or decision
- `status`: PENDING or PROCESSED
- `timestamp`: When the feedback was created or last updated
## Example Usage
Here's an example of how to set up and manage a HITL workflow using KaibanJS:
```js
// Creating a task that requires validation
const task = new Task({
title: "Analyze market trends",
description: "Research and summarize current market trends for our product",
assignedTo: "Alice",
externalValidationRequired: true
});
// Set up the workflow status change listener before starting
team.onWorkflowStatusChange((status) => {
if (status === 'BLOCKED') {
// Check for tasks awaiting validation
const tasksAwaitingValidation = team.getTasksByStatus('AWAITING_VALIDATION');
tasksAwaitingValidation.forEach(task => {
console.log(`Task awaiting validation: ${task.title}`);
// Example: Automatically validate the task
team.validateTask(task.id);
// Alternatively, provide feedback if the task needs revision
// This could be based on human review or automated criteria
// team.provideFeedback(task.id, "Please include more data on competitor pricing.");
});
} else if (status === 'FINISHED') {
console.log('Workflow completed successfully!');
console.log('Final result:', team.getWorkflowResult());
}
});
// Start the workflow and handle the promise
team.start()
.then((output) => {
if (output.status === 'FINISHED') {
console.log('Workflow completed with result:', output.result);
}
})
.catch(error => {
console.error('Workflow encountered an error:', error);
});
```
## Task Statuses
The system includes the following task statuses, which apply to all tasks throughout the entire workflow, including but not limited to HITL processes:
- `TODO`: Task is queued for initiation, awaiting processing.
- `DOING`: Task is actively being worked on by an agent.
- `BLOCKED`: Progress on the task is halted due to dependencies or obstacles.
- `REVISE`: Task requires additional review or adjustments based on feedback.
- `AWAITING_VALIDATION`: Task is completed but requires validation or approval.
- `VALIDATED`: Task has been validated and confirmed as correctly completed.
- `DONE`: Task is fully completed and requires no further action.
These statuses are defined in the [TASK_STATUS_enum](https://github.com/kaiban-ai/KaibanJS/blob/main/src/utils/enums.js#L58) and can be accessed throughout the system for consistency.
## Task State Flow Diagram
Below is a text-based representation of the task state flow diagram:
```
+---------+
| TODO |
+---------+
|
v
+---------+
+--->| DOING |
| +---------+
| |
| +----+----+----+----+
| | | |
v v v v
+-------------+ +---------+ +------------------+
| BLOCKED | | REVISE | | AWAITING_ |
+-------------+ +---------+ | VALIDATION |
| | +------------------+
| | |
| | v
| | +--------------+
| | | VALIDATED |
| | +--------------+
| | |
| | v
+--------------+----------------+
|
v
+---------+
| DONE |
+---------+
```
## Task State Transitions
1. **TODO to DOING**:
- When a task is picked up by an agent to work on.
2. **DOING to BLOCKED**:
- If the task encounters an obstacle or dependency that prevents progress.
3. **DOING to AWAITING_VALIDATION**:
- Only for tasks created with `externalValidationRequired = true`.
- Occurs when the agent completes the task but it needs human validation.
4. **DOING to DONE**:
- For tasks that don't require external validation.
- When the agent successfully completes the task.
5. **AWAITING_VALIDATION to VALIDATED**:
- When a human approves the task without changes.
6. **AWAITING_VALIDATION to REVISE**:
- If the human provides feedback or requests changes during validation.
7. **VALIDATED to DONE**:
- Automatic transition after successful validation.
8. **REVISE to DOING**:
- When the agent starts working on the task again after receiving feedback.
9. **BLOCKED to DOING**:
- When the obstacle is removed and the task can proceed.
## HITL Workflow Integration
1. **Requiring External Validation**:
- Set `externalValidationRequired: true` when creating a task to ensure it goes through human validation before completion.
2. **Initiating HITL**:
- Use `team.provideFeedback(taskId, feedbackContent)` at any point to move a task to REVISE state.
3. **Validating Tasks**:
- Use `team.validateTask(taskId)` to approve a task, moving it from AWAITING_VALIDATION to VALIDATED, then to DONE.
- Use `team.provideFeedback(taskId, feedbackContent)` to request revisions, moving the task from AWAITING_VALIDATION to REVISE.
4. **Processing Feedback**:
- The system automatically processes feedback given through the `provideFeedback()` method.
- Agents handle pending feedback before continuing with the task.
## Feedback in HITL
In KaibanJS, human interventions are implemented through a feedback system. Each task maintains a `feedbackHistory` array to track these interactions.
### Feedback Structure
Each feedback entry in the `feedbackHistory` consists of:
- `content`: The human input or decision
- `status`: The current state of the feedback
- `timestamp`: When the feedback was created or last updated
### Feedback Statuses
KaibanJS uses two primary statuses for feedback:
- `PENDING`: Newly added feedback that hasn't been addressed yet
- `PROCESSED`: Feedback that has been successfully addressed and incorporated
This structure allows for clear tracking of human interventions and their resolution throughout the task lifecycle.
## React Example
```jsx
import React, { useState, useEffect } from 'react';
import { team } from './teamSetup'; // Assume this is where your team is initialized
function WorkflowBoard() {
const [tasks, setTasks] = useState([]);
const [workflowStatus, setWorkflowStatus] = useState('');
const store = team.useStore();
useEffect(() => {
const unsubscribeTasks = store.subscribe(
state => state.tasks,
(tasks) => setTasks(tasks)
);
const unsubscribeStatus = store.subscribe(
state => state.teamWorkflowStatus,
(status) => setWorkflowStatus(status)
);
return () => {
unsubscribeTasks();
unsubscribeStatus();
};
}, []);
const renderTaskColumn = (status, title) => (
{title}
{tasks.filter(task => task.status === status).map(task => (
{task.title}
{task.description}
{status === 'AWAITING_VALIDATION' && (
store.getState().validateTask(task.id)}>
Validate
)}
store.getState().provideFeedback(task.id, "Sample feedback")}>
Provide Feedback
))}
);
return (
Task Board - Workflow Status: {workflowStatus}
{renderTaskColumn('TODO', 'To Do')}
{renderTaskColumn('DOING', 'In Progress')}
{renderTaskColumn('BLOCKED', 'Blocked')}
{renderTaskColumn('AWAITING_VALIDATION', 'Waiting for Feedback')}
{renderTaskColumn('DONE', 'Done')}
store.getState().startWorkflow()}>Start Workflow
);
}
export default WorkflowBoard;
```
## Conclusion
By implementing Human in the Loop through KaibanJS's feedback and validation system, you can create a more robust, ethical, and accurate task processing workflow. This feature ensures that critical decisions benefit from human judgment while maintaining the efficiency of automated processes for routine operations.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/get-started/01-Quick Start.md
//--------------------------------------------
// File: ./src/get-started/01-Quick Start.md
//--------------------------------------------
---
title: Quick Start
description: Get started with KaibanJS in under 1 minute. Learn how to set up your Kaiban Board, create AI agents, watch them complete tasks in real-time, and deploy your board online.
---
# Quick Start Guide
Get your AI-powered workflow up and running in minutes with KaibanJS!
:::tip[Try it Out in the Playground!]
Before diving into the installation and coding, why not experiment directly with our interactive playground? [Try it now!](https://www.kaibanjs.com/share/f3Ek9X5dEWnvA3UVgKUQ)
:::
## Quick Demo
Watch this 1-minute video to see KaibanJS in action:
VIDEO
## Prerequisites
- Node.js (v14 or later) and npm (v6 or later)
- An API key for OpenAI or Anthropic, Google AI, or another [supported AI service](../llms-docs/01-Overview.md).
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
## Setup
**1. Run the KaibanJS initializer in your project directory:**
```bash
npx kaibanjs@latest init
```
This command sets up KaibanJS in your project and opens the Kaiban Board in your browser.
**2. Set up your API key:**
- Create or edit the `.env` file in your project root
- Add your API key (example for OpenAI):
```
VITE_OPENAI_API_KEY=your-api-key-here
```
**3. Restart your Kaiban Board:**
```bash
npm run kaiban
```
## Using Your Kaiban Board
1. In the Kaiban Board, you'll see a default example workflow.
2. Click "Start Workflow" to run the example and see KaibanJS in action.
3. Observe how agents complete tasks in real-time on the Task Board.
4. Check the Results Overview for the final output.
## Customizing Your Workflow
1. Open `team.kban.js` in your project root.
2. Modify the agents and tasks to fit your needs. For example:
```javascript
import { Agent, Task, Team } from 'kaibanjs';
const researcher = new Agent({
name: 'Researcher',
role: 'Information Gatherer',
goal: 'Find latest info on AI developments'
});
const writer = new Agent({
name: 'Writer',
role: 'Content Creator',
goal: 'Summarize research findings'
});
const researchTask = new Task({
description: 'Research recent breakthroughs in AI',
agent: researcher
});
const writeTask = new Task({
description: 'Write a summary of AI breakthroughs',
agent: writer
});
const team = new Team({
name: 'AI Research Team',
agents: [researcher, writer],
tasks: [researchTask, writeTask]
});
export default team;
```
3. Save your changes and the Kaiban Board will automatically reload to see your custom workflow in action.
## Deploying Your Kaiban Board
To share your Kaiban Board online:
1. Run the deployment command:
```bash
npm run kaiban:deploy
```
2. Follow the prompts to deploy your board to Vercel.
3. Once deployed, you'll receive a URL where your Kaiban Board is accessible online.
This allows you to share your AI-powered workflows with team members or clients, enabling collaborative work on complex tasks.
## Quick Tips
- Use `npm run kaiban` to start your Kaiban Board anytime.
- Press `Ctrl+C` in the terminal to stop the Kaiban Board.
- Click "Share Team" in the Kaiban Board to generate a shareable link.
- Access our LLM-friendly documentation at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt) to integrate with your AI IDE or LLM tools.
## AI Development Integration
KaibanJS documentation is available in an LLM-friendly format, making it easy to:
- Feed into AI coding assistants for context-aware development
- Use with AI IDEs for better code completion and suggestions
- Integrate with LLM tools for automated documentation processing
Simply point your AI tool to `https://docs.kaibanjs.com/llms-full.txt` to access our complete documentation in a format optimized for large language models.
## Flexible Integration
KaibanJS isn't limited to the Kaiban Board. You can integrate it directly into your projects, create custom UIs, or run agents without a UI. Explore our tutorials for [React](./05-Tutorial:%20React%20+%20AI%20Agents.md) and [Node.js](./06-Tutorial:%20Node.js%20+%20AI%20Agents.md) integration to unleash the full potential of KaibanJS in various development contexts.
## Next Steps
- Experiment with different agent and task combinations.
- Try integrating KaibanJS into your existing projects.
- Check out the full documentation for advanced features.
For more help or to connect with the community, visit [kaibanjs.com](https://www.kaibanjs.com).
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/get-started/02-Core Concepts Overview.md
//--------------------------------------------
// File: ./src/get-started/02-Core Concepts Overview.md
//--------------------------------------------
---
title: Core Concepts Overview
description: A brief introduction to the fundamental concepts of KaibanJS - Agents, Tasks, Teams, and Tools.
---
VIDEO
KaibanJS is built around four primary components: `Agents`, `Tools`, `Tasks`, and `Teams`. Understanding how these elements interact is key to leveraging the full power of the framework.
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
### Agents
Agents are the autonomous actors in KaibanJS. They can:
- Process information
- Make decisions
- Execute actions
- Interact with other agents
Each agent has:
- A unique role or specialty
- Defined capabilities
- Specific goals or objectives
### Tools
Tools are specific capabilities or functions that agents can use to perform their tasks. They:
- Extend an agent's abilities
- Can include various functionalities like web searches, data processing, or external API interactions
- Allow for customization and specialization of agents
### Tasks
Tasks represent units of work within the system. They:
- Encapsulate specific actions or processes
- Can be assigned to agents
- Have defined inputs and expected outputs
- May be part of larger workflows or sequences
### Teams
Teams are collections of agents working together. They:
- Combine diverse agent capabilities
- Enable complex problem-solving
- Facilitate collaborative workflows
### How Components Work Together
1. **Task Assignment**: Tasks are created and assigned to appropriate agents or teams.
2. **Agent Processing**: Agents analyze tasks, make decisions, and take actions based on their capabilities, tools, and the task requirements.
3. **Tool Utilization**: Agents use their assigned tools to gather information, process data, or perform specific actions required by their tasks.
4. **Collaboration**: In team settings, agents communicate and coordinate to complete more complex tasks, often sharing the results of their tool usage.
5. **Workflow Execution**: Multiple tasks can be chained together to form workflows, allowing for sophisticated, multi-step processes.
6. **Feedback and Iteration**: Results from completed tasks can inform future actions or trigger new tasks, creating dynamic and adaptive systems.
By combining these core concepts, KaibanJS enables the creation of flexible, intelligent systems capable of handling a wide range of applications, from simple automation to complex decision-making processes. The integration of Tools with Agents, Tasks, and Teams allows for highly customizable and powerful AI-driven solutions.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/get-started/03-The Kaiban Board.md
//--------------------------------------------
// File: ./src/get-started/03-The Kaiban Board.md
//--------------------------------------------
---
title: The Kaiban Board
description: Transform your AI workflow with Kaiban Board. Easily create, visualize, and manage AI agents locally, then deploy with a single click. Your all-in-one solution for intuitive AI development and deployment.
---
VIDEO
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
## From Kanban to Kaiban: Evolving Workflow Management for AI
The Kaiban Board draws inspiration from the time-tested [Kanban methodology](https://en.wikipedia.org/wiki/Kanban_(development)), adapting it for the unique challenges of AI agent management.
But what exactly is Kanban, and how does it translate to the world of AI?
### The Kanban Methodology: A Brief Overview
Kanban, Japanese for "visual signal" or "card," originated in Toyota's manufacturing processes in the late 1940s. It's a visual system for managing work as it moves through a process, emphasizing continuous delivery without overburdening the development team.
Key principles of Kanban include:
- Visualizing workflow
- Limiting work in progress
- Managing flow
- Making process policies explicit
- Implementing feedback loops
> If you have worked with a team chances are you have seen a kanban board in action. Popular tools like Trello, ClickUp, and Jira use kanban to help teams manage their work.
## KaibanJS: Kanban for AI Agents
KaibanJS takes the core principles of Kanban and applies them to the complex world of AI agent management. Just as Kanban uses cards to represent work items, KaibanJS uses powerful, state management techniques to represent AI agents, their tasks, and their current states.
With KaibanJS, you can:
- Create, visualize, and manage AI agents, tasks, and teams
- Orchestrate your AI agents' workflows
- Visualize your AI agents' workflows in real-time
- Track the progress of tasks as they move through various stages
- Identify bottlenecks and optimize your AI processes
- Collaborate more effectively with your team on AI projects
By representing agentic processes in a familiar Kanban-style board, KaibanJS makes it easier for both technical and non-technical team members to understand and manage complex AI workflows.
## The Kaiban Board: Your AI Workflow Visualization Center
The Kaiban Board serves as a visual representation of your AI agent workflows powered by the KaibanJS framework. It provides an intuitive interface that allows you to:
1. **Visualize AI agents** created and configured through KaibanJS
2. **Monitor agent tasks and interactions** in real-time
3. **Track progress** across different stages of your AI workflow
4. **Identify issues** quickly for efficient troubleshooting
The KaibanJS framework itself enables you to:
- **Create and configure AI agents** programmatically
- **Deploy your AI solutions** with a simple command
Whether you're a seasoned AI developer or just getting started with multi-agent systems, the combination of the Kaiban Board for visualization and KaibanJS for development offers a powerful yet accessible way to manage your AI projects.
Experience the Kaiban Board for yourself and see how it can streamline your AI development process. Visit our [playground](https://www.kaibanjs.com/playground) to get started today!
:::tip[We Love Feedback!]
Spotted something funky in the docs? Got a brilliant idea? We're all ears! [Submit an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues) and help us make KaibanJS even more awesome!
:::
### ./src/get-started/04-Using the Kaiban Board.md
//--------------------------------------------
// File: ./src/get-started/04-Using the Kaiban Board.md
//--------------------------------------------
---
title: Using the Kaiban Board
description: Master the intuitive Kaiban Board interface. Learn to effortlessly create, monitor, and manage AI workflows through our powerful visual tools. Perfect for teams looking to streamline their AI development process.
---
Welcome to the Kaiban Board - your visual command center for AI agent workflows! This guide will walk you through the key features of our intuitive interface, helping you get started quickly.
VIDEO
**Try It Live!**
Experience the Kaiban Board [here](https://www.kaibanjs.com/playground).
## Interface Overview
The Kaiban Board is divided into 3 main sections:
1. **Team Setup**
2. **Task Board**
3. **Results Overview**
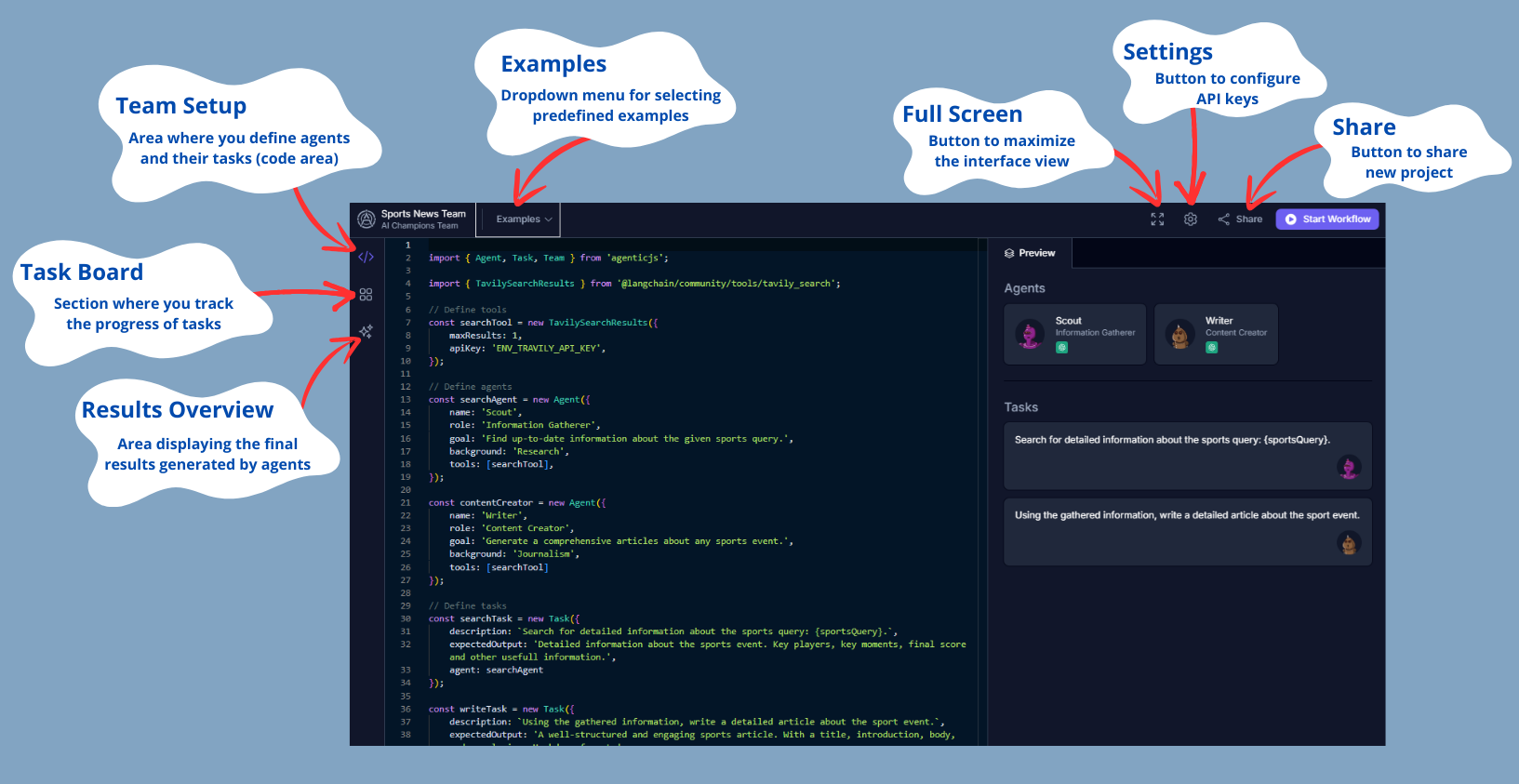
## 1. Team Setup
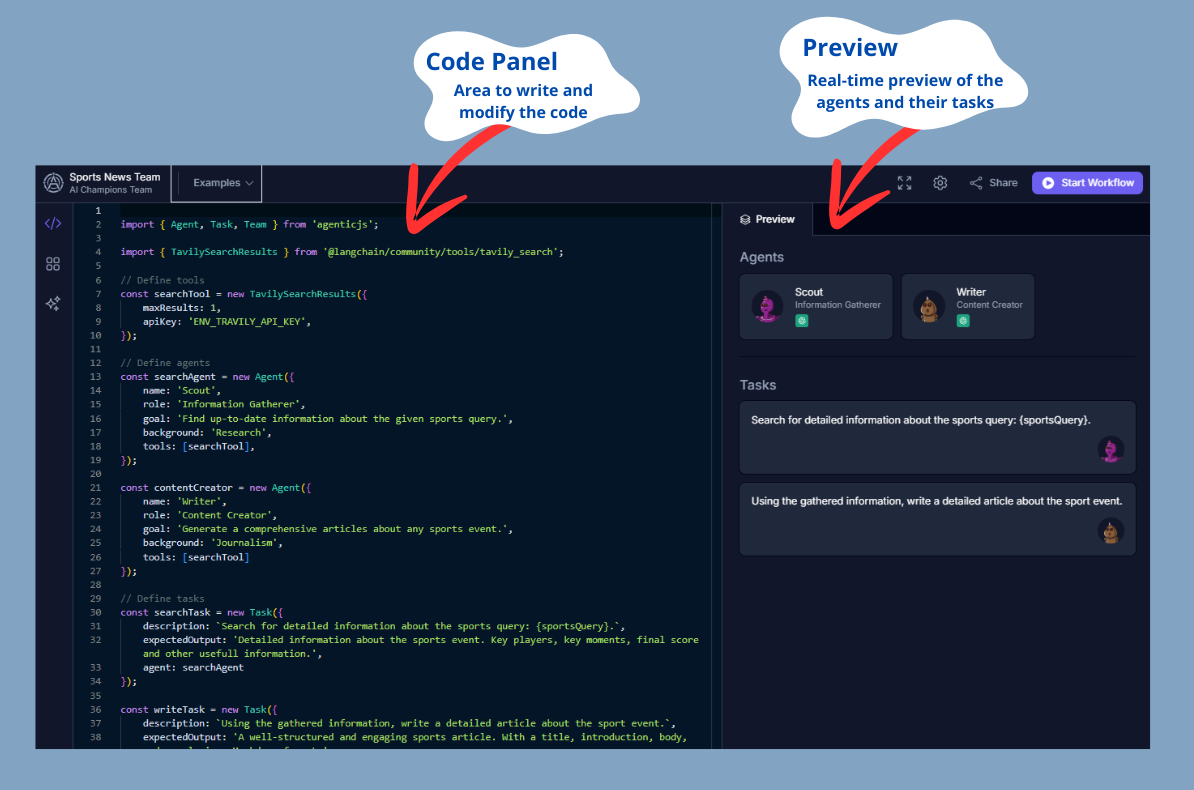
The "Team Setup" area is where you define the agents and their tasks. Although we won't discuss code in this tutorial, it's important to know that this is where you configure the agents' behavior. By default, there will always be an example selected in this area.
- **Code Panel**: On the left, you can view and edit the code that defines the tools, agents, and tasks.
- **Preview**: On the right, you can see a real-time preview of the configured agents, including their names, roles, and the tasks they will perform.
At the top of the interface, you will find a dropdown menu called **"Examples."** Here you can select from several predefined examples to view and execute. These examples are ready to use and help you understand how multi-agent systems are configured.
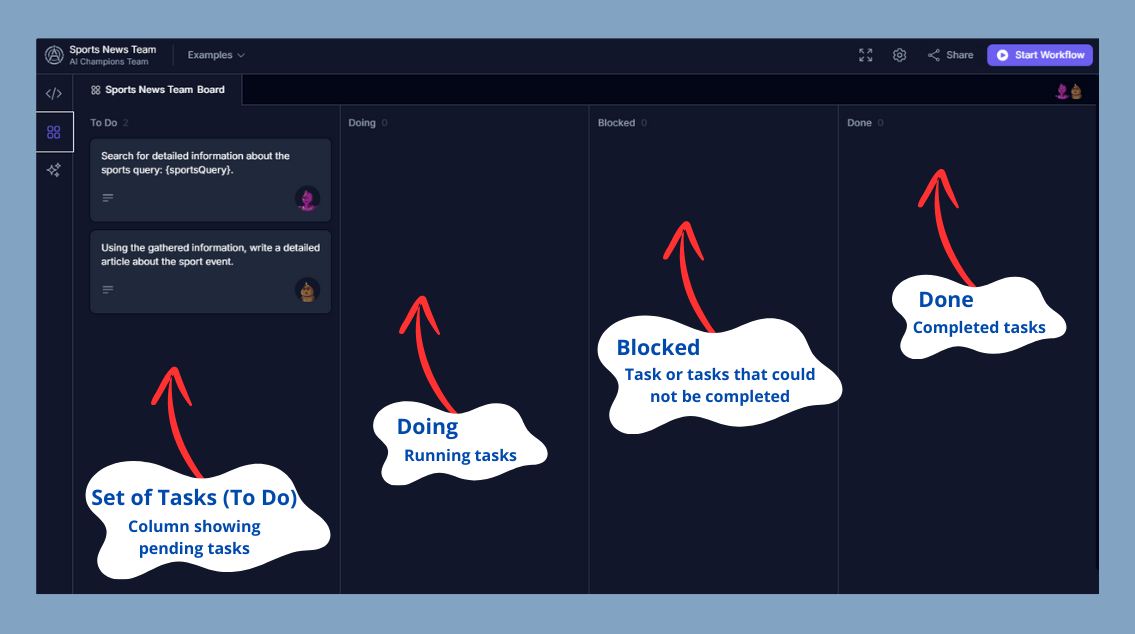
## 2. Task Board
The "Task Board" is a crucial section where you can track the progress of tasks assigned to the agents. It is like a Trello or Jira Kanban board but for AI Agents.
### 2.1. Task Panel
This panel organizes tasks into several columns:
- **To Do**: Pending tasks.
- **Doing**: Tasks in progress.
- **Blocked**: Tasks that cannot proceed due to a blockage.
- **Done**: Completed tasks.
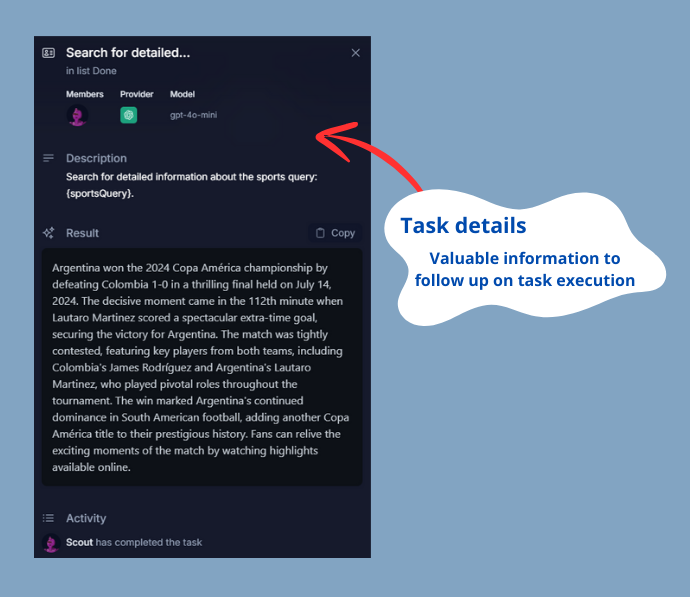
### 2.2. Task Details
For each task, you can see additional details such as its description, the activities carried out, the progress of execution, and partial results. The detailed view includes:
- **Members**: Shows the agents assigned to the task along with their roles, helping you understand who is responsible for each part of the task.
- **Provider**: Indicates the AI service provider being used, ensuring you know which backend is powering the task.
- **Model**: Displays the specific AI model utilized, giving insight into the type of processing being applied.
- **Description**: Provides a brief but detailed overview of what the task aims to achieve, ensuring clarity of purpose.
- **Result**: Shows the outcome generated by the agent, which can be copied for further use. This is where you see the final output based on the agent's processing.
- **Activity**: Lists all the steps and actions taken by the agent during the task. This log includes statuses and updates, providing a comprehensive view of the task's progress and any issues encountered.
### 2.3. General Activity
You can also see an overview of all agents' activities by clicking the "Activity" button.
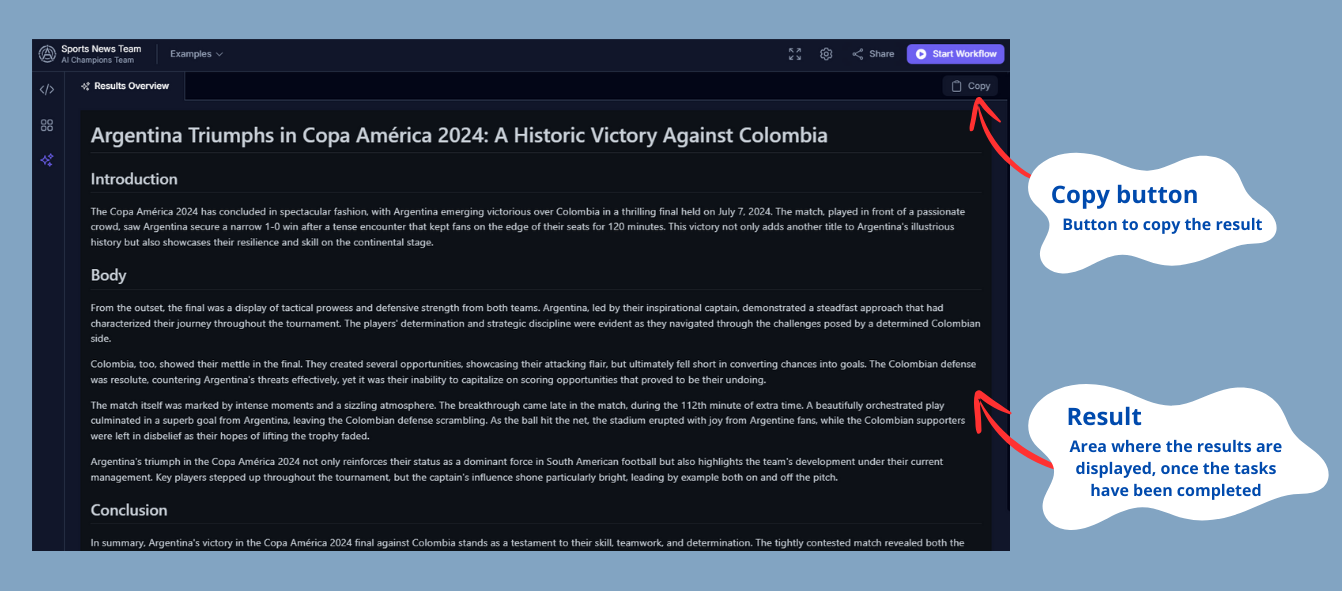
## 3. Results Overview
The **"Results Overview"** area displays the final results generated by the agents once they complete their tasks.
- **Results**: Here you will find the reports generated or any other output produced by the agents. You can copy these results directly from the interface for further use.
## Control Toolbar (Top Right)
Besides the main sections, the interface includes some important additional features:
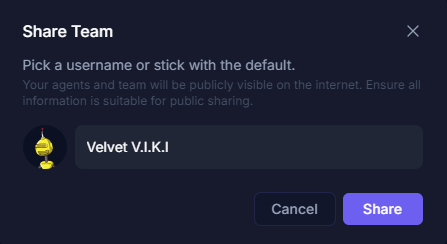
1. **Share Team**: The "Share" button allows you to generate a link to share your current agent configuration with others. You can name your multi-agent system and easily share it.
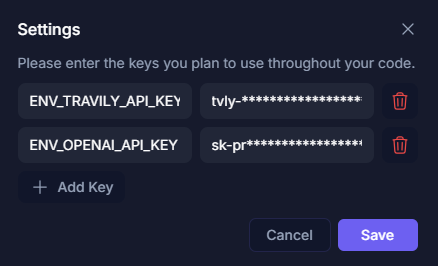
2. **API Keys Configuration**: The settings button allows the user to enter their API Keys to change the AI model used. This provides flexibility to work with different AI service providers according to the project's needs.
3. **Full Screen**: The full-screen button allows you to maximize the interface for a more comprehensive and detailed view of the playground. This is especially useful when working with complex configurations and needing more visual space.
4. **Start Workflow**: This button initiates the execution of the tasks by the agents defined in your code.
## Basic Interface Usage
1. **Create and Configure Agents and Their Tasks**:
- Modify the default code or copy new code to create and configure agents. Observe how it reflects in real-time in the preview.
2. **Start the Workflow**:
- Press "Start Workflow" to begin executing the tasks.
3. **Monitor Progress**:
- Use the Task Board to track the progress of tasks and check specific details if needed.
4. **Review Results**:
- Once tasks are completed, review the results in the "Results Overview" area.
5. **Share and Configure**:
- Use the "Share" and "Settings" buttons to share your project and configure your API Keys.
## Conclusion
The Kaiban Board simplifies AI integration, enabling you to visualize, manage, and share AI agents with ease. Ideal for developers, project managers, and researchers, this tool facilitates efficient operation and collaboration without the need for complex setups. Enhance your projects by leveraging the power of AI with our user-friendly platform.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/get-started/05-Tutorial: React + AI Agents.md
//--------------------------------------------
// File: ./src/get-started/05-Tutorial: React + AI Agents.md
//--------------------------------------------
---
title: React + AI Agents (Tutorial)
description: A step-by-step guide to creating your first project with KaibanJS, from setup to execution using Vite and React.
---
Welcome to our tutorial on integrating KaibanJS with React using Vite to create a dynamic blogging application. This guide will take you through setting up your environment, defining AI agents, and building a simple yet powerful React application that utilizes AI to research and generate blog posts about the latest news on any topic you choose.
By the end of this tutorial, you will have a solid understanding of how to leverage AI within a React application, making your projects smarter and more interactive.
:::tip[For the Lazy: Jump Right In!]
If you're eager to see the final product in action without following the step-by-step guide first, we've got you covered. Click the link below to access a live version of the project running on CodeSandbox.
[View the completed project on a CodeSandbox](https://stackblitz.com/~/github.com/kaiban-ai/kaibanjs-react-demo?file=src/App.jsx)
Feel free to return to this tutorial to understand how we built each part of the application step by step!
:::
## Project Setup
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
#### 1. Create a new Vite React project:
```bash
# Create a new Vite project with React template
npm create vite@latest kaibanjs-react-demo -- --template react
cd kaibanjs-react-demo
npm install
# Start the development server
npm run dev
```
#### 2. Install necessary dependencies:
```bash
npm install kaibanjs
# For tool using
npm install @langchain/community --legacy-peer-deps
```
**Note:** You may need to install the `@langchain/community` package with the `--legacy-peer-deps` flag due to compatibility issues.
#### 3. Create a `.env` file in the root of your project and add your API keys:
```
VITE_TRAVILY_API_KEY=your-tavily-api-key
VITE_OPENAI_API_KEY=your-openai-api-key
```
#### To obtain these API keys you must follow the steps below.
**For the Tavily API key:**
1. Visit https://tavily.com/
2. Sign up for an account or log in if you already have one.
3. Navigate to your dashboard or API section.
4. Generate a new API key or copy your existing one.
**For the OpenAI API key:**
1. Go to https://platform.openai.com/
2. Sign up for an account or log in to your existing one.
3. Navigate to the API keys section in your account settings.
4. Create a new API key or use an existing one.
**Note:** Remember to keep these API keys secure and never share them publicly. The `.env` file should be added to your `.gitignore` file to prevent it from being committed to version control. For production environments, consider more secure solutions such as secret management tools or services that your hosting provider might offer.
## Defining Agents and Tools
Create a new file `src/blogTeam.js`. We'll use this file to set up our agents, tools, tasks, and team.
#### 1. First, let's import the necessary modules and set up our search tool:
```javascript
import { Agent, Task, Team } from 'kaibanjs';
import { TavilySearchResults } from '@langchain/community/tools/tavily_search';
// Define the search tool used by the Research Agent
const searchTool = new TavilySearchResults({
maxResults: 5,
apiKey: import.meta.env.VITE_TRAVILY_API_KEY
});
```
#### 2. Now, let's define our agents:
```javascript
// Define the Research Agent
const researchAgent = new Agent({
name: 'Ava',
role: 'News Researcher',
goal: 'Find and summarize the latest news on a given topic',
background: 'Experienced in data analysis and information gathering',
tools: [searchTool]
});
// Define the Writer Agent
const writerAgent = new Agent({
name: 'Kai',
role: 'Content Creator',
goal: 'Create engaging blog posts based on provided information',
background: 'Skilled in writing and content creation',
tools: []
});
```
## Creating Tasks
In the same `blogTeam.js` file, let's define the tasks for our agents:
```javascript
// Define Tasks
const researchTask = new Task({
title: 'Latest news research',
description: 'Research the latest news on the topic: {topic}',
expectedOutput: 'A summary of the latest news and key points on the given topic',
agent: researchAgent
});
const writingTask = new Task({
title: 'Blog post writing',
description: 'Write a blog post about {topic} based on the provided research',
expectedOutput: 'An engaging blog post summarizing the latest news on the topic in Markdown format',
agent: writerAgent
});
```
## Assembling a Team
Still in `blogTeam.js`, let's create our team of agents:
```javascript
// Create the Team
const blogTeam = new Team({
name: 'AI News Blogging Team',
agents: [researchAgent, writerAgent],
tasks: [researchTask, writingTask],
env: { OPENAI_API_KEY: import.meta.env.VITE_OPENAI_API_KEY }
});
export { blogTeam };
```
## Building the React Component
Now, let's create our main React component. Replace the contents of `src/App.jsx` with the following code:
```jsx
import React, { useState } from 'react';
import './App.css';
import { blogTeam } from './blogTeam';
function App() {
// Setting up State
const [topic, setTopic] = useState('');
const [blogPost, setBlogPost] = useState('');
const [stats, setStats] = useState(null);
// Connecting to the KaibanJS Store
const useTeamStore = blogTeam.useStore();
const {
agents,
tasks,
teamWorkflowStatus
} = useTeamStore(state => ({
agents: state.agents,
tasks: state.tasks,
teamWorkflowStatus: state.teamWorkflowStatus
}));
const generateBlogPost = async () => {
// We'll implement this function in the next step
alert('The generateBlogPost function needs to be implemented.');
};
return (
AI Agents News Blogging Team
Generate
Status {teamWorkflowStatus}
{/* Generated Blog Post */}
{blogPost ? (
blogPost
) : (
ℹ️ No blog post available yet Enter a topic and click 'Generate' to see results here.
)}
{/* We'll add more UI elements in the next steps */}
{/* Agents Here */}
{/* Tasks Here */}
{/* Stats Here */}
);
}
export default App;
```
This basic structure sets up our component with state management and a simple UI. Let's break it down step-by-step:
### Step 1: Setting up State
We use the `useState` hook to manage our component's state:
```jsx
const [topic, setTopic] = useState('');
const [blogPost, setBlogPost] = useState('');
const [stats, setStats] = useState(null);
```
These state variables will hold the user's input topic, the generated blog post, and statistics about the generation process.
### Step 2: Connecting to the KaibanJS Store
We use the `const useTeamStore = blogTeam.useStore();` to access the current state of our AI team:
```jsx
const {
agents,
tasks,
teamWorkflowStatus
} = useTeamStore(state => ({
agents: state.agents,
tasks: state.tasks,
teamWorkflowStatus: state.teamWorkflowStatus
}));
```
This allows us to track the status of our agents, tasks, and overall workflow.
### Step 3: Implementing the Blog Post Generation Function
Now, let's implement the `generateBlogPost` function:
```jsx
const generateBlogPost = async () => {
setBlogPost('');
setStats(null);
try {
const output = await blogTeam.start({ topic });
if (output.status === 'FINISHED') {
setBlogPost(output.result);
const { costDetails, llmUsageStats, duration } = output.stats;
setStats({
duration: duration,
totalTokenCount: llmUsageStats.inputTokens + llmUsageStats.outputTokens,
totalCost: costDetails.totalCost
});
} else if (output.status === 'BLOCKED') {
console.log(`Workflow is blocked, unable to complete`);
}
} catch (error) {
console.error('Error generating blog post:', error);
}
};
```
This function starts the KaibanJS workflow, updates the blog post and stats when finished, and handles any errors.
### Step 4: Implementing UX Best Practices for System Feedback
In this section, we'll implement UX best practices to enhance how the system provides feedback to users. By refining the UI elements that communicate internal processes, activities, and statuses, we ensure that users remain informed and engaged, maintaining a clear understanding of the application's operations as they interact with it.
**First, let's add a section to show the status of our agents:**
```jsx
Agents
{agents && agents.map((agent, index) => (
{agent.name}
{agent.status}
))}
```
This code displays a list of agents, showing each agent's name and current status. It provides visibility into which agents are active and what they're doing.
**Next, let's display the tasks that our agents are working on:**
```jsx
Tasks
{tasks && tasks.map((task, index) => (
{task.title}
{task.status}
))}
```
This code creates a list of tasks, showing the title and current status of each task. It helps users understand what steps are involved in generating the blog post.
**Finally, let's add a section to display statistics about the blog post generation process:**
```jsx
Stats
{stats ? (
Total Tokens:
{stats.totalTokenCount}
Total Cost:
${stats.totalCost.toFixed(4)}
Duration:
{stats.duration} ms
) : (
ℹ️ No stats generated yet.
{blogPost ? (
{blogPost}
) : (
ℹ️ No blog post available yet Enter a topic and click 'Generate' to see results here.
)}
AI Agents News Blogging Team
Generate
Status {teamWorkflowStatus}
{/* Generated Blog Post */}
{blogPost ? (
blogPost
) : (
ℹ️ No blog post available yet Enter a topic and click 'Generate' to see results here.
)}
{/* We'll add more UI elements in the next steps */}
{/* Agents Here */}
{/* Tasks Here */}
{/* Stats Here */}
);
}
```
This basic structure sets up our component with state management and a simple UI. Let's break it down step-by-step:
### Step 1: Setting up State
We use the `useState` hook to manage our component's state:
```js
const [topic, setTopic] = useState('');
const [blogPost, setBlogPost] = useState('');
const [stats, setStats] = useState(null);
```
These state variables will hold the user's input topic, the generated blog post, and statistics about the generation process.
### Step 2: Connecting to the KaibanJS Store
We use the `const useTeamStore = blogTeam.useStore();` to access the current state of our AI team:
```js
const {
agents,
tasks,
teamWorkflowStatus
} = useTeamStore(state => ({
agents: state.agents,
tasks: state.tasks,
teamWorkflowStatus: state.teamWorkflowStatus
}));
```
This allows us to track the status of our agents, tasks, and overall workflow.
### Step 3: Implementing the Blog Post Generation Function
Now, let's implement the `generateBlogPost` function:
```js
const generateBlogPost = async () => {
setBlogPost('');
setStats(null);
try {
const output = await blogTeam.start({ topic });
if (output.status === 'FINISHED') {
setBlogPost(output.result);
const { costDetails, llmUsageStats, duration } = output.stats;
setStats({
duration: duration,
totalTokenCount: llmUsageStats.inputTokens + llmUsageStats.outputTokens,
totalCost: costDetails.totalCost
});
} else if (output.status === 'BLOCKED') {
console.log(`Workflow is blocked, unable to complete`);
}
} catch (error) {
console.error('Error generating blog post:', error);
}
};
```
This function starts the KaibanJS workflow, updates the blog post and stats when finished, and handles any errors.
### Step 4: Implementing UX Best Practices for System Feedback
In this section, we'll implement UX best practices to enhance how the system provides feedback to users. By refining the UI elements that communicate internal processes, activities, and statuses, we ensure that users remain informed and engaged, maintaining a clear understanding of the application's operations as they interact with it.
**First, let's add a section to show the status of our agents:**
```js
Agents
{agents && agents.map((agent, index) => (
{agent.name}
{agent.status}
))}
```
This code displays a list of agents, showing each agent's name and current status. It provides visibility into which agents are active and what they're doing.
**Next, let's display the tasks that our agents are working on:**
```js
Tasks
{tasks && tasks.map((task, index) => (
{task.title}
{task.status}
))}
```
This code creates a list of tasks, showing the title and current status of each task. It helps users understand what steps are involved in generating the blog post.
**Finally, let's add a section to display statistics about the blog post generation process:**
```js
Stats
{stats ? (
Total Tokens:
{stats.totalTokenCount}
Total Cost:
${stats.totalCost.toFixed(4)}
Duration:
{stats.duration} ms
) : (
ℹ️ No stats generated yet.
{blogPost ? (
{blogPost}
) : (
ℹ️ No blog post available yet Enter a topic and click 'Generate' to see results here.
)}
Task Statuses
{tasks.map(task => (
{task.description}: Status - {task.status}
))}
);
};
export default TaskStatusComponent;
```
### Integration Examples
To help you get started quickly, here are examples of KaibanJS integrated with different JavaScript frameworks:
- **NodeJS + KaibanJS:** Enhance your backend services with AI capabilities. [Try it on CodeSandbox](https://codesandbox.io/p/github/darielnoel/KaibanJS-NodeJS/main).
- **React + Vite + KaibanJS:** Build dynamic frontends with real-time AI features. [Explore on CodeSandbox](https://codesandbox.io/p/github/darielnoel/KaibanJS-React-Vite/main).
## Conclusion
Integrating KaibanJS with your preferred JavaScript framework unlocks powerful possibilities for enhancing your applications with AI-driven interactions and functionalities. Whether you're building a simple interactive UI in React or managing complex backend logic in Node.js, KaibanJS provides the tools you need to embed sophisticated AI capabilities into your projects.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/how-to/04-Implementing RAG with KaibanJS.md
//--------------------------------------------
// File: ./src/how-to/04-Implementing RAG with KaibanJS.md
//--------------------------------------------
---
title: Implementing a RAG tool
description: Learn to enhance your AI projects with the power of Retrieval Augmented Generation (RAG). This step-by-step tutorial guides you through creating the WebRAGTool in KaibanJS, enabling your AI agents to access and utilize web-sourced, context-specific data with ease.
---
In this hands-on tutorial, we'll build a powerful WebRAGTool that can fetch and process web content dynamically, enhancing your AI agents' ability to provide accurate and contextually relevant responses.
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
We will be using:
- [KaibanJS](https://kaibanjs.com/): For Agents Orchestration.
- [LangChain](https://js.langchain.com/docs/introduction/): For the WebRAGTool Creation.
- [OpenAI](https://openai.com/): For LLM inference and Embeddings.
- [React](https://reactjs.org/): For the UI.
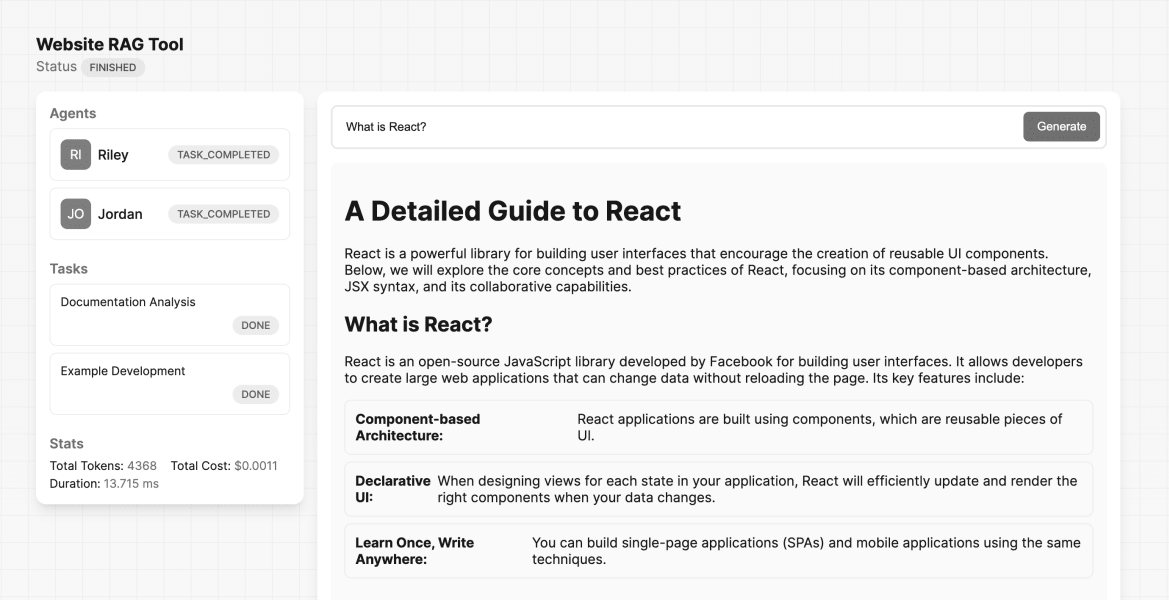
## Final Result
A basic React App that uses the WebRAGTool to answer questions about the React documentation website.
:::tip[For the Lazy: Jump Right In!]
Ready to dive straight into the code? You can find the complete project on CodeSandbox by following the link below:
[View the completed project on a CodeSandbox](https://stackblitz.com/~/github.com/kaiban-ai/kaibanjs-web-rag-tool-demo)
Feel free to explore the project and return to this tutorial for a detailed walkthrough!
:::
## Parts of the Tutorial
:::note[Note]
This tutorial assumes you have a basic understanding of the KaibanJS framework and custom tool creation. If you're new to these topics, we recommend reviewing the following resources before proceeding:
- [Getting Started with KaibanJS](/category/get-started)
- [Creating Custom Tools in KaibanJS](/tools-docs/custom-tools/Create%20a%20Custom%20Tool)
These guides will provide you with the foundational knowledge needed to make the most of this tutorial.
:::
On this tutorial we will:
1. **Explain Key Components of a RAG Tool:**
A RAG (Retrieval Augmented Generation) tool typically consists of several key components that work together to enhance the capabilities of language models. Understanding these components is crucial before we dive into building our WebRAGTool.
2. **Create a WebRAGTool:**
The Tool will fetch content from specified web pages. Processes and indexes this content. Uses the indexed content to answer queries with context-specific information.
3. **Test the WebRAGTool:**
We'll create a simple test to verify that the WebRAGTool works as expected.
4. **Integrate the WebRAGTool into your KaibanJS Environment:**
We'll create AI agents that utilize the WebRAGTool.These agents will be organized into a KaibanJS team, demonstrating multi-agent collaboration.
5. **Create a simple UI:**
We will point you to an existing example project that uses React to create a simple UI for interacting with the WebRAGTool.
Let's Get Started.
## Key Components of a RAG Tool
Before we start building the WebRAGTool, let's understand the key components that make it work:
| Component | Description | Example/Usage in Tutorial |
|-----------|-------------|---------------------------|
| Source | Where information is obtained for processing and storage. Your knowledge base. PDFs, Web PAges, Excell, API, etc. | Web pages (HTML content) |
| Vector Storage | Specialized database for storing and retrieving high-dimensional vectors representing semantic content | In-memory storage |
| Operation Type | How we interact with vector storage and source | Write: Indexing web content - Read: Querying for answers |
| LLM (Large Language Model) | AI model that processes natural language and generates responses | gpt-4o-mini |
| Embedder | Converts text into vector representations capturing semantic meaning | OpenAIEmbeddings |
#### By combining these components, our WebRAGTool will be able to:
- fetch web content,
- convert it into searchable vector form.
- store it efficiently.
- use it to generate informed responses to user queries.
Now that we've covered the key components of our RAG system, let's dive into the implementation steps.
## Create a WebRAGTool
### 1. Setting Up the Environment
First, let's install the necessary dependencies and set up our project:
```bash
npm install kaibanjs @langchain/core @langchain/community @langchain/openai zod cheerio
```
Now, create a new file called `WebRAGTool.js` and add the following imports and class structure:
```javascript
import { Tool } from '@langchain/core/tools';
import 'cheerio';
import { CheerioWebBaseLoader } from '@langchain/community/document_loaders/web/cheerio';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { OpenAIEmbeddings, ChatOpenAI } from '@langchain/openai';
import { createStuffDocumentsChain } from 'langchain/chains/combine_documents';
import { StringOutputParser } from '@langchain/core/output_parsers';
import { MemoryVectorStore } from 'langchain/vectorstores/memory';
import { ChatPromptTemplate } from '@langchain/core/prompts';
import { z } from 'zod';
export class WebRAGTool extends Tool {
constructor(fields) {
super(fields);
this.url = fields.url;
this.name = 'web_rag';
this.description = 'This tool implements Retrieval Augmented Generation (RAG) by dynamically fetching and processing web content from a specified URL to answer user queries.';
this.schema = z.object({
query: z.string().describe('The query for which to retrieve and generate answers.'),
});
}
async _call(input) {
try {
// Create Source Loader Here
// Implement Vector Storage Here
// Configure LLM and Embedder Here
// Build RAG Pipeline Here
// Generate and Return Response Here
} catch (error) {
console.error('Error running the WebRAGTool:', error);
throw error;
}
}
}
```
This boilerplate sets up the basic structure of our `WebRAGTool` class. We've included placeholders for each major component we'll be implementing in the subsequent steps. This approach provides a clear roadmap for what we'll be building and where each piece fits into the overall structure.
### 2. Creating the Source Loader
In this step, we set up the source loader to fetch and process web content. We use CheerioWebBaseLoader to load HTML content from the specified URL, and then split it into manageable chunks using RecursiveCharacterTextSplitter. This splitting helps in processing large documents while maintaining context.
Replace the "Create Source Loader Here" comment with the following code:
```js
// Create Source Loader Here
const loader = new CheerioWebBaseLoader(this.url);
const docs = await loader.load();
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits = await textSplitter.splitDocuments(docs);
```
### 3. Implementing the Vector Storage
Here, we create a vector store to efficiently store and retrieve our document chunks. We use MemoryVectorStore for in-memory storage and OpenAIEmbeddings to convert our text chunks into vector representations. This allows for semantic search and retrieval of relevant information.
Replace the "Implement Vector Storage Here" comment with:
```js
// Implement Vector Storage Here
const vectorStore = await MemoryVectorStore.fromDocuments(
splits,
new OpenAIEmbeddings({
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
})
);
const retriever = vectorStore.asRetriever();
```
### 4. Configuring the LLM and Embedder
In this step, we initialize the language model (LLM) that will generate responses based on the retrieved information. We're using OpenAI's ChatGPT model here. Note that the embedder was already configured in the vector store creation step.
Replace the "Configure LLM and Embedder Here" comment with:
```js
// Configure LLM and Embedder Here
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
});
```
### 5. Building the RAG Pipeline
Now we create the RAG (Retrieval-Augmented Generation) pipeline. This involves setting up a prompt template to structure input for the language model and creating a chain that combines the LLM, prompt, and document processing.
Replace the "Build RAG Pipeline Here" comment with:
```js
// Build RAG Pipeline Here
const prompt = ChatPromptTemplate.fromTemplate(`
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:`);
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
});
```
### 6. Generate and Return Response
Finally, we use our RAG pipeline to generate a response. This involves retrieving relevant documents based on the input query and then using the RAG chain to generate a response that combines the query with the retrieved context.
Replace the "Generate and Return Response Here" comment with:
```js
// Generate and Return Response Here
const retrievedDocs = await retriever.invoke(input.query);
const response = await ragChain.invoke({
question: input.query,
context: retrievedDocs,
});
return response;
```
### Complete WebRAGTool Implementation
After following the detailed step-by-step explanation and building each part of the `WebRAGTool`, here is the complete code for the tool. You can use this to verify your implementation or as a quick start to copy and paste into your project:
```javascript
import { Tool } from '@langchain/core/tools';
import 'cheerio';
import { CheerioWebBaseLoader } from '@langchain/community/document_loaders/web/cheerio';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { OpenAIEmbeddings, ChatOpenAI } from '@langchain/openai';
import { createStuffDocumentsChain } from 'langchain/chains/combine_documents';
import { StringOutputParser } from '@langchain/core/output_parsers';
import { MemoryVectorStore } from 'langchain/vectorstores/memory';
import { ChatPromptTemplate } from '@langchain/core/prompts';
import { z } from 'zod';
export class WebRAGTool extends Tool {
constructor(fields) {
super(fields);
// Store the URL from which to fetch content
this.url = fields.url;
// Define the tool's name and description
this.name = 'web_rag';
this.description =
'This tool implements Retrieval Augmented Generation (RAG) by dynamically fetching and processing web content from a specified URL to answer user queries. It leverages external web sources to provide enriched responses that go beyond static datasets, making it ideal for applications needing up-to-date information or context-specific data. To use this tool effectively, specify the target URL and query parameters, and it will retrieve relevant documents to generate concise, informed responses based on the latest content available online';
// Define the schema for the input query using Zod for validation
this.schema = z.object({
query: z
.string()
.describe('The query for which to retrieve and generate answers.'),
});
}
async _call(input) {
try {
// Step 1: Load Content from the Specified URL
const loader = new CheerioWebBaseLoader(this.url);
const docs = await loader.load();
// Step 2: Split the Loaded Documents into Chunks
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 1000,
chunkOverlap: 200,
});
const splits = await textSplitter.splitDocuments(docs);
// Step 3: Create a Vector Store from the Document Chunks
const vectorStore = await MemoryVectorStore.fromDocuments(
splits,
new OpenAIEmbeddings({
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
})
);
// Step 4: Initialize a Retriever
const retriever = vectorStore.asRetriever();
// Step 5: Define the Prompt Template for the Language Model
const prompt = ChatPromptTemplate.fromTemplate(`
You are an assistant for question-answering tasks. Use the following pieces of retrieved context to answer the question. If you don't know the answer, just say that you don't know. Use three sentences maximum and keep the answer concise.
Question: {question}
Context: {context}
Answer:`);
// Step 6: Initialize the Language Model (LLM)
const llm = new ChatOpenAI({
model: 'gpt-4o-mini',
apiKey: import.meta.env.VITE_OPENAI_API_KEY,
});
// Step 7: Create the RAG Chain
const ragChain = await createStuffDocumentsChain({
llm,
prompt,
outputParser: new StringOutputParser(),
});
// Step 8: Retrieve Relevant Documents Based on the User's Query
const retrievedDocs = await retriever.invoke(input.query);
// Step 9: Generate the Final Response
const response = await ragChain.invoke({
question: input.query,
context: retrievedDocs,
});
// Step 10: Return the Generated Response
return response;
} catch (error) {
// Log and rethrow any errors that occur during the process
console.error('Error running the WebRAGTool:', error);
throw error;
}
}
}
```
This complete code snippet is ready to be integrated into your project. It encompasses all the functionality discussed in the tutorial, from fetching and processing data to generating responses based on the retrieved information.
## Testing the WebRAGTool
Once you have implemented the `WebRAGTool`, testing it is crucial to ensure it functions as intended. Below is a step-by-step guide on how to set up and run a simple test. This test mimics a realistic use-case, similar to how an agent might invoke the tool within the `KaibanJS` framework once it is integrated into an AI team.
First, ensure that you have the tool script in your project. Here’s how you import the `WebRAGTool` that you've developed:
```javascript
import { WebRAGTool } from './WebRAGTool'; // Adjust the path as necessary
```
Next, define a function to test the tool by executing a query through the RAG process:
```javascript
async function testTool() {
// Create an instance of the WebRAGTool with a specific URL
const tool = new WebRAGTool({
url: 'https://react.dev/',
});
// Invoke the tool with a query and log the output
const queryResponse = await tool.invoke({ query: "What is React?" });
console.log(queryResponse);
}
testTool();
```
**Example Console Output:**
```
React is a JavaScript library for building user interfaces using components, allowing developers to create dynamic web applications. It emphasizes the reuse of components to build complex UIs in a structured manner. Additionally, React fosters a large community, enabling collaboration and support among developers and designers.
```
The console output provided is an example of the potential result when using RAG to enhance query responses. It illustrates the tool's capability to provide detailed and context-specific information, which is critical for building more knowledgeable and responsive AI systems. Remember, the actual output may vary depending on updates to the source content and modifications in the processing logic of your tool.
## Integrating the WebRAGTool into Your KaibanJS Environment
Once you have developed the `WebRAGTool`, integrating it into your KaibanJS environment involves a few key steps that link the tool to an agent capable of utilizing its capabilities. This integration ensures that your AI agents can effectively use the RAG functionality to enhance their responses based on the latest web content.
### Step 1: Import the Tool
First, ensure the tool is accessible within your project by importing it where you plan to use it:
```javascript
import { WebRAGTool } from './WebRAGTool'; // Adjust the path as necessary based on your project structure
```
### Step 2: Initialize the Tool
Create an instance of the `WebRAGTool`, specifying the URL of the data source you want the tool to retrieve information from. This URL should point to the web content relevant to your agent's queries:
```javascript
const webRAGTool = new WebRAGTool({
url: 'https://react.dev/' // Specify the URL to fetch content from, tailored to your agent's needs
});
```
### Step 3: Assign the Tool to an Agent
With the tool initialized, the next step is to assign it to an agent. This involves creating an agent and configuring it to use this tool as part of its resources to answer queries. Here, we configure an agent whose role is to analyze and summarize documentation:
```javascript
import { Agent, Task, Team } from 'kaibanjs';
const docAnalystAgent = new Agent({
name: 'Riley',
role: 'Documentation Analyst',
goal: 'Analyze and summarize key sections of React documentation',
background: 'Expert in software development and technical documentation',
tools: [webRAGTool] // Assign the WebRAGTool to this agent
});
```
By following these steps, you seamlessly integrate RAG into your KaibanJS application, enabling your agents to utilize dynamically retrieved web content to answer queries more effectively. This setup not only makes your agents more intelligent and responsive but also ensures that they can handle queries with the most current data available, enhancing user interaction and satisfaction.
### Step 4: Integrate the Team into a Real Application
After setting up your individual agents and their respective tools, the next step is to combine them into a team that can be integrated into a real-world application. This demonstrates how different agents with specialized skills can work together to achieve complex tasks.
Here's how you can define a team of agents using the `KaibanJS` framework and prepare it for integration into an application:
```javascript
import { Agent, Task, Team } from 'kaibanjs';
import { WebRAGTool } from './tool';
const webRAGTool = new WebRAGTool({
url: 'https://react.dev/',
});
// Define the Documentation Analyst Agent
const docAnalystAgent = new Agent({
name: 'Riley',
role: 'Documentation Analyst',
goal: 'Analyze and summarize key sections of React documentation',
background: 'Expert in software development and technical documentation',
tools: [webRAGTool], // Include the WebRAGTool in the agent's tools
});
// Define the Developer Advocate Agent
const devAdvocateAgent = new Agent({
name: 'Jordan',
role: 'Developer Advocate',
goal: 'Provide detailed examples and best practices based on the summarized documentation',
background: 'Skilled in advocating and teaching React technologies',
tools: [],
});
// Define Tasks
const analysisTask = new Task({
title: 'Documentation Analysis',
description: 'Analyze the React documentation sections related to {topic}',
expectedOutput: 'A summary of key features and updates in the React documentation on the given topic',
agent: docAnalystAgent,
});
const exampleTask = new Task({
title: 'Example Development',
description: 'Provide a detailed explanation of the analyzed documentation',
expectedOutput: 'A detailed guide with examples and best practices in Markdown format',
agent: devAdvocateAgent,
});
// Create the Team
const reactDevTeam = new Team({
name: 'AI React Development Team',
agents: [docAnalystAgent, devAdvocateAgent],
tasks: [analysisTask, exampleTask],
env: { OPENAI_API_KEY: import.meta.env.VITE_OPENAI_API_KEY }
});
export { reactDevTeam };
```
**Using the Team in an Application:**
Now that you have configured your team, you can integrate it into an application. This setup allows the team to handle complex queries about React, processing them through the specialized agents to provide comprehensive answers and resources.
For a practical demonstration, revisit the interactive example we discussed earlier in the tutorial:
[View the example project on CodeSandbox](https://stackblitz.com/~/github.com/kaiban-ai/kaibanjs-web-rag-tool-demo)
This link leads to the full project setup where you can see the team in action. You can run queries, observe how the agents perform their tasks, and get a feel for the interplay of different components within a real application.
## Conclusion
By following this tutorial, you've learned how to create a custom RAG tool that fetches and processes web content, enhancing your AI's ability to provide accurate and contextually relevant responses.
This comprehensive guide should give you a thorough understanding of building and integrating a RAG tool in your AI applications. If you have any questions or need further clarification on any step, feel free to ask!
## Acknowledgments
Thanks to [@Valdozzz](https://twitter.com/valdozzz1) for suggesting this valuable addition. Your contributions help drive innovation within our community!
## Feedback
:::tip[We Love Feedback!]
Is there something unclear or quirky in this tutorial? Have a suggestion or spotted an issue? Help us improve by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). Your input is valuable!
:::
### ./src/how-to/05-Using Typescript.md
//--------------------------------------------
// File: ./src/how-to/05-Using Typescript.md
//--------------------------------------------
---
title: Using Typescript
description: KaibanJS is type supported. You can use TypeScript to get better type checking and intellisense with powerful IDEs like Visual Studio Code.
---
## Setup
To start using typescript, you need to install the typescript package:
```bash
npm install typescript --save-dev
```
You may optionally create a custom tsconfig file to configure your typescript settings. A base settings file looks like this:
```json
{
"compilerOptions": {
"noEmit": true,
"strict": true,
"module": "NodeNext",
"moduleResolution": "NodeNext",
"esModuleInterop": true,
"skipLibCheck": true
},
"exclude": ["node_modules"]
}
```
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
Now you can follow the, [Quick Start](/docs/get-started/01-Quick%20Start.md) guide to get started with KaibanJS using TypeScript.
## Types
Base classes are already type suported and you can import them like below:-
```typescript
import { Agent, Task, Team } from "kaibanjs";
```
For any other specific types, can call them like below:-
```typescript
import type { IAgentParams, ITaskParams } from "kaibanjs";
```
## Learn more
This guide has covered the basics of setting up TypeScript for use with KaibanJS. But if you want to learn more about TypeScript itself, there are many resources available to help you.
We recommend the following resources:
- [TypeScript Handbook](https://www.typescriptlang.org/docs/handbook/intro.html) - The TypeScript handbook is the official documentation for TypeScript, and covers most key language features.
- [TypeScript Discord](https://discord.com/invite/typescript) - The TypeScript Community Discord is a great place to ask questions and get help with TypeScript issues.
### ./src/how-to/06-API Key Management.md
//--------------------------------------------
// File: ./src/how-to/06-API Key Management.md
//--------------------------------------------
---
title: API Key Management
description: Learn about the pros and cons of using API keys in browser-based applications with KaibanJS. Understand when it's acceptable, the potential risks, and best practices for securing your keys in production environments.
---
# API Key Management
Managing API keys securely is one of the most important challenges when building applications that interact with third-party services, like Large Language Models (LLMs). With KaibanJS, we offer a flexible approach to handle API keys based on your project's stage and security needs, while providing a proxy boilerplate to ensure best practices.
This guide will cover:
1. **The pros and cons of using API keys in the browser**.
2. **Legitimate use cases** for browser-based API key usage.
3. **Secure production environments** using our **Kaiban LLM Proxy**.
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
---
## API Key Handling with KaibanJS
When working with third-party APIs like OpenAI, Anthropic, and Google Gemini, you need to authenticate using API keys. KaibanJS supports two approaches to handle API keys:
### 1. Developer-Owned Keys (DOK)
This is the "move fast and break things" mode, where developers can provide API keys directly in the browser. This approach is recommended for:
- Rapid prototyping
- Local development
- Quick demos or hackathons
- Personal projects with limited risk
**Benefits**:
- **Fast setup**: No need to set up a server or proxy, allowing for quick iteration.
- **Direct interaction**: Makes testing and development easier, with the ability to communicate directly with the API.
**Drawbacks**:
- **Security risks**: Exposes API keys to the browser, allowing them to be easily viewed and potentially abused.
- **Limited to development environments**: Not recommended for production use.
### 2. Proxy Setup for Production
When building production-grade applications, exposing API keys in the frontend is a significant security risk. KaibanJS recommends using a backend proxy to handle API requests securely.
The **Kaiban LLM Proxy** offers a pre-built solution to ensure your API keys are hidden while still allowing secure, efficient communication with the LLM providers.
**Benefits**:
- **API keys are protected**: They remain on the server and never reach the frontend.
- **Vendor compliance**: Some LLM providers restrict frontend API access, requiring server-side communication.
- **Improved security**: You can add rate-limiting, request logging, and other security features to the proxy.
---
## What are API Keys?
API keys are unique identifiers provided by third-party services that allow access to their APIs. They authenticate your requests and often have usage quotas. In a production environment, these keys must be protected to prevent unauthorized use and abuse.
---
## Is It Safe to Use API Keys in the Browser?
Using API keys directly in the browser is convenient for development but risky in production. Browser-exposed keys can be easily viewed in developer tools, potentially leading to abuse or unauthorized access.
### Pros of Using API Keys in the Browser
1. **Ease of Setup**: Ideal for rapid prototyping, where speed is a priority.
2. **Direct Communication**: Useful when you want to quickly test API interactions without setting up backend infrastructure.
3. **Developer Flexibility**: Provides a way for users to supply their own API keys in scenarios like BYOAK (Bring Your Own API Key).
### Cons of Using API Keys in the Browser
1. **Security Risks**: Keys exposed in the browser can be easily stolen or misused.
2. **Provider Restrictions**: Some LLM providers, such as OpenAI and Anthropic, may restrict API key usage to backend-only.
3. **Lack of Control**: Without a backend, it's harder to manage rate-limiting, request logging, or prevent abuse.
---
## Legitimate Use Cases for Browser-Based API Keys
There are scenarios where using API keys in the browser is acceptable:
1. **Internal Tools or Demos**: Trusted internal environments or demos, where the risk of key exposure is low.
2. **BYOAK (Bring Your Own API Key)**: If users are supplying their own keys, it may be acceptable to use them in the browser, as they control their own credentials.
3. **Personal Projects**: For small-scale or personal applications where security risks are minimal.
4. **Non-Critical APIs**: For APIs with low security risks or restricted access, where exposing keys is less of a concern.
---
## Secure Production Setup: The Kaiban LLM Proxy
The **Kaiban LLM Proxy** is an open-source utility designed to serve as a **starting point** for securely handling API requests to multiple Large Language Model (LLM) providers. While Kaiban LLM Proxy provides a quick and easy solution, you are free to build or use your own proxies using your preferred technologies, such as **AWS Lambda**, **Google Cloud Functions**, or **other serverless solutions**.
- **Repository URL**: [Kaiban LLM Proxy GitHub Repo](https://github.com/kaiban-ai/kaiban-llm-proxy)
This proxy example is intended to demonstrate a simple and secure way to manage API keys, but it is not the only solution. You can clone the repository to get started or adapt the principles outlined here to build a proxy using your chosen stack or infrastructure.
### Cloning the Proxy
To explore or modify the Kaiban LLM Proxy, you can clone the repository:
```bash
git clone https://github.com/kaiban-ai/kaiban-llm-proxy.git
cd kaiban-llm-proxy
npm install
npm run dev
```
The proxy is flexible and can be deployed or adapted to other environments. You can create your own proxy in your preferred technology stack, providing full control over security, scalability, and performance.
---
## Best Practices for API Key Security
1. **Use Environment Variables**: Always store API keys in environment variables, never hardcode them in your codebase.
2. **Set Up a Proxy**: Use the Kaiban LLM Proxy for production environments to ensure API keys are never exposed.
3. **Monitor API Usage**: Implement logging and monitoring to track usage patterns and detect any abnormal activity.
4. **Use Rate Limiting**: Apply rate limiting on your proxy to prevent abuse or overuse of API resources.
---
## Conclusion
KaibanJS offers the flexibility to use API keys in the browser during development while providing a secure path to production with the **Kaiban LLM Proxy**. For rapid development, the **DOK approach** allows you to move quickly, while the **proxy solution** ensures robust security for production environments.
By leveraging KaibanJS and the proxy boilerplate, you can balance speed and security throughout the development lifecycle. Whether you’re building a quick demo or a production-grade AI application, we’ve got you covered.
### ./src/how-to/07-Deployment Options.md
//--------------------------------------------
// File: ./src/how-to/07-Deployment Options.md
//--------------------------------------------
---
title: Deploying Your Kaiban Board
description: Learn how to deploy your Kaiban Board, a Vite-based single-page application, to various hosting platforms.
---
# Deploying Your Kaiban Board
Want to get your board online quickly? From your project's root directory, run:
```bash
npm run kaiban:deploy
```
This command will automatically build and deploy your board to Vercel's global edge network. You'll receive a unique URL for your deployment, and you can configure a custom domain later if needed.
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
## Manual Deployment Options
The Kaiban Board is a Vite-based single-page application (SPA) that can be deployed to any web server. Here's how to deploy manually:
### Building the Kaiban Board
1. Navigate to your `.kaiban` folder:
```bash
cd .kaiban
```
2. Install dependencies if you haven't already:
```bash
npm install
```
3. Build the application:
```bash
npm run build
```
This will create a `dist` directory with your production-ready Kaiban Board.
### Deployment Platforms
You can deploy your Kaiban Board to:
- **GitHub Pages**: Perfect for projects already hosted on GitHub
- **Netlify**: Offers automatic deployments from Git
- **Any Static Web Server**: Simply copy the contents of the `.kaiban/dist` directory to your web server's public directory
- **Docker**: Containerize your board using any lightweight web server to serve the static files
## Environment Variables
Remember to set your environment variables in your hosting platform:
```env
VITE_OPENAI_API_KEY=your_api_key_here
# Add other environment variables as needed
```
## Best Practices
1. **Build Process**
- Always run a production build before deploying
- Test the build locally using `npm run preview`
- Ensure all environment variables are properly set
2. **Security**
- Configure HTTPS for your domain
- Set up proper CORS headers if needed
- Keep your API keys secure
3. **Performance**
- Enable caching for static assets
- Configure compression
- Use a CDN if needed
## Troubleshooting
Common deployment issues:
1. **Blank Page After Deployment**
- Check if the base URL is configured correctly in `vite.config.js`
- Verify all assets are being served correctly
- Check browser console for errors
2. **Environment Variables Not Working**
- Ensure variables are prefixed with `VITE_`
- Rebuild the application after changing environment variables
- Verify variables are properly set in your hosting platform
:::tip[Need Help?]
Join our [Discord community](https://kaibanjs.com/discord) for deployment support and troubleshooting assistance.
:::
:::info[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/how-to/07-Structured-Output.md
//--------------------------------------------
// File: ./src/how-to/07-Structured-Output.md
//--------------------------------------------
---
title: Structured Output
description: Define the exact shape and format of your AI agent outputs to ensure consistent and predictable responses.
---
# How to Use Structured Output Validation
This guide shows you how to implement structured output validation in your KaibanJS tasks using Zod schemas.
:::tip[Using AI Development Tools?]
Our documentation is available in an LLM-friendly format at [docs.kaibanjs.com/llms-full.txt](https://docs.kaibanjs.com/llms-full.txt). Feed this URL directly into your AI IDE or coding assistant for enhanced development support!
:::
## Prerequisites
- KaibanJS installed in your project
- Basic understanding of Zod schema validation
## Setting Up Schema Validation
### Step 1: Install Dependencies
```bash
npm install zod
```
### Step 2: Import Required Modules
```javascript
const { z } = require('zod');
const { Task } = require('kaibanjs');
```
### Step 3: Define Your Schema
```javascript
const task = new Task({
description: "Extract article metadata",
expectedOutput: "Get the article's title and list of tags", // Human-readable instructions
outputSchema: z.object({ // Validation schema
title: z.string(),
tags: z.array(z.string())
})
});
```
## Common Use Cases
### 1. Product Information Extraction
```javascript
const productSchema = z.object({
name: z.string(),
price: z.number(),
features: z.array(z.string()),
availability: z.boolean()
});
const task = new Task({
description: "Extract product details from the provided text",
expectedOutput: "Extract product name, price, features, and availability status",
outputSchema: productSchema
});
```
### 2. Meeting Summary Generation
```javascript
const meetingSummarySchema = z.object({
title: z.string(),
date: z.string(),
participants: z.array(z.string()),
keyPoints: z.array(z.string()),
actionItems: z.array(z.object({
task: z.string(),
assignee: z.string(),
dueDate: z.string().optional()
}))
});
const task = new Task({
description: "Generate a structured summary of the meeting",
expectedOutput: "Create a meeting summary with title, date, participants, key points, and action items",
outputSchema: meetingSummarySchema
});
```
## Handling Schema Validation
When an agent's output doesn't match your schema:
1. The agent enters an `OUTPUT_SCHEMA_VALIDATION_ERROR` state
2. It receives feedback about the validation error
3. It attempts to correct the output format as part of the agentic loop
You can monitor these validation events using the workflowLogs:
```javascript
function monitorSchemaValidation(teamStore) {
// Subscribe to workflow logs updates
teamStore.subscribe(
state => state.workflowLogs,
(logs) => {
// Find validation error logs
const validationErrors = logs.filter(log =>
log.logType === "AgentStatusUpdate" &&
log.agentStatus === "OUTPUT_SCHEMA_VALIDATION_ERROR"
);
if (validationErrors.length > 0) {
const latestError = validationErrors[validationErrors.length - 1];
console.log('Schema validation failed:', latestError.logDescription);
console.log('Error details:', latestError.metadata);
}
}
);
}
// Example usage
const teamStore = myTeam.useStore();
monitorSchemaValidation(teamStore);
```
This approach allows you to:
- Track all schema validation attempts
- Access detailed error information
- Monitor the agent's attempts to correct the output
- Implement custom error handling based on the validation results
## Best Practices
1. **Keep Schemas Focused**
- Define schemas that capture only the essential data
- Avoid overly complex nested structures
2. **Clear Instructions**
- Provide detailed `expectedOutput` descriptions
- Include example outputs in your task description
3. **Flexible Validation**
- Use `optional()` for non-required fields
- Consider using `nullable()` when appropriate
- Implement `default()` values where it makes sense
4. **Error Recovery**
- Implement proper error handling
- Consider retry strategies for failed validations
- Log validation errors for debugging
## Troubleshooting
Common issues and solutions:
1. **Invalid Types**
```javascript
// Instead of
price: z.string()
// Use
price: z.number()
```
2. **Missing Required Fields**
```javascript
// Make fields optional when needed
dueDate: z.string().optional()
```
3. **Array Validation**
```javascript
// Validate array items
tags: z.array(z.string())
// With minimum length
tags: z.array(z.string()).min(1)
```
## Limitations
- Schema validation occurs after response generation
- Complex schemas may require multiple validation attempts
- Nested schemas might need more specific agent instructions
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/01-Overview.md
//--------------------------------------------
// File: ./src/llms-docs/01-Overview.md
//--------------------------------------------
---
title: Overview
description: An overview of Language Model support and integration in KaibanJS
---
> KaibanJS provides robust support for a wide range of Language Models (LLMs), enabling you to harness the power of state-of-the-art AI in your applications. This section of the documentation covers both built-in models and custom integrations, giving you the flexibility to choose the best LLM for your specific needs.
## Structure of LLMs Documentation
Our LLMs documentation is organized into two main categories:
1. **Built-in Models**: These are LLMs that come pre-integrated with KaibanJS, offering a streamlined setup process.
2. **Custom Integrations**: These are additional LLMs that require some manual configuration but expand your options for specialized use cases.
### Built-in Models
KaibanJS provides out-of-the-box support for several leading LLM providers:
- **OpenAI**: Access to models like GPT-4 and GPT-3.5-turbo.
- **Anthropic**: Integration with Claude models.
- **Google**: Utilize Google's Gemini models.
- **Mistral**: Leverage Mistral AI's efficient language models.
These built-in integrations offer a simplified setup process, allowing you to quickly incorporate powerful AI capabilities into your agents.
### Custom Integrations
For users requiring specialized models or specific configurations, KaibanJS supports custom integrations with various LLM providers:
- **Ollama**: Run open-source models locally.
- **Cohere**: Access Cohere's suite of language models.
- **Azure OpenAI**: Use OpenAI models through Azure's cloud platform.
- **Cloudflare**: Integrate with Cloudflare's AI services.
- **Groq**: Utilize Groq's high-performance inference engines.
- **Other Integrations**: Explore additional options for specialized needs.
These custom integrations provide flexibility for advanced use cases, allowing you to tailor your LLM setup to your specific requirements.
## Key Features
- **Flexibility**: Choose from a wide range of models to suit your specific use case.
- **Scalability**: Easily switch between different models as your needs evolve.
- **Customization**: Fine-tune model parameters for optimal performance.
- **Langchain Compatibility**: Leverage the full power of Langchain's LLM integrations.
## Getting Started
To begin using LLMs in KaibanJS:
1. Decide whether a built-in model or custom integration best suits your needs.
2. Follow the setup instructions for your chosen model in the relevant documentation section.
3. Configure your agent with the appropriate LLM settings.
For built-in models, you can typically get started with just a few lines of code:
```javascript
const agent = new Agent({
name: 'AI Assistant',
role: 'Helper',
llmConfig: {
provider: 'openai', // or 'anthropic', 'google', 'mistral'
model: 'gpt-4', // specific model name
}
});
```
For custom integrations, you'll need to import and configure the specific LLM before passing it to your agent:
```javascript
import { SomeLLM } from "some-llm-package";
const customLLM = new SomeLLM({
// LLM-specific configuration
});
const agent = new Agent({
name: 'Custom AI Assistant',
role: 'Specialized Helper',
llmInstance: customLLM
});
```
## Next Steps
Explore the subsections for detailed information on each built-in model and custom integration. Each page provides specific setup instructions, configuration options, and best practices for using that particular LLM with KaibanJS.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/02-Model Providers API Keys.md
//--------------------------------------------
// File: ./src/llms-docs/02-Model Providers API Keys.md
//--------------------------------------------
---
title: Model Providers API Keys
description: Learn how to manage API keys for different language model providers in KaibanJS.
---
When working with multiple language models in KaibanJS, you need to manage API keys for different providers. This guide explains two approaches to configuring API keys: directly in the `llmConfig` of each agent, or globally through the `env` property when creating a team.
:::warning[API Key Security]
Always use environment variables for API keys instead of hardcoding them. This enhances security and simplifies key management across different environments.
**Example:**
```javascript
apiKey: process.env.YOUR_API_KEY
```
Never commit API keys to version control. Use a `.env` file or a secure secrets management system for sensitive information.
Please refer to [API Keys Management](/how-to/API%20Key%20Management) to learn more about handling API Keys safely.
:::
## Specifying API Keys Directly in llmConfig
You can include the API key directly in the `llmConfig` of each agent. This method is useful when agents use different providers or when you prefer to encapsulate the key with the agent configuration.
```js
import { Agent } from 'kaibanjs';
// Agent with Google's Gemini model
const emma = new Agent({
name: 'Emma',
role: 'Initial Drafting',
goal: 'Outline core functionalities',
llmConfig: {
provider: 'google',
model: 'gemini-1.5-pro',
apiKey: 'ENV_GOOGLE_API_KEY'
}
});
// Agent with Anthropic's Claude model
const lucas = new Agent({
name: 'Lucas',
role: 'Technical Specification',
goal: 'Draft detailed technical specifications',
llmConfig: {
provider: 'anthropic',
model: 'claude-3-5-sonnet-20240620',
apiKey: 'ENV_ANTHROPIC_API_KEY'
}
});
// Agent with OpenAI's GPT-4 model
const mia = new Agent({
name: 'Mia',
role: 'Final Review',
goal: 'Ensure accuracy and completeness of the final document',
llmConfig: {
provider: 'openai',
model: 'gpt-4o',
apiKey: 'ENV_OPENAI_API_KEY'
}
});
```
## Using the `env` Property for Team-Wide Configuration
If all agents in your team use the same AI provider, or you prefer a centralized location for managing API keys, use the `env` property when defining the team. This method simplifies management, especially when using environment variables or configuration files.
```js
import { Agent, Task, Team } from 'kaibanjs';
const team = new Team({
name: 'Multi-Model Support Team',
agents: [emma, lucas, mia],
tasks: [], // Define tasks here
env: {
OPENAI_API_KEY: 'your-open-ai-api-key',
ANTHROPIC_API_KEY: 'your-anthropic-api-key',
GOOGLE_API_KEY: 'your-google-api-key'
} // Centralized environment variables for the team
});
// Listen to the workflow status changes
// team.onWorkflowStatusChange((status) => {
// console.log("Workflow status:", status);
// });
team.start()
.then((output) => {
console.log("Workflow status:", output.status);
console.log("Result:", output.result);
})
.catch((error) => {
console.error("Workflow encountered an error:", error);
});
```
## Choosing the Right Approach
Both approaches for managing API keys are valid, and the choice between them depends on your project's structure and your preference for managing API keys.
- Use the `llmConfig` approach when:
- Your agents use different providers
- You want to keep API keys closely associated with specific agents
- You need fine-grained control over API key usage
- Use the `env` property approach when:
- All or most agents use the same provider
- You prefer centralized management of API keys
- You're using environment variables or configuration files for sensitive information
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/built-in-models/01-Overview.md
//--------------------------------------------
// File: ./src/llms-docs/built-in-models/01-Overview.md
//--------------------------------------------
---
title: Overview
description: An introduction to pre-integrated Language Models in KaibanJS
---
> KaibanJS offers seamless integration with several leading LLM providers, allowing you to quickly implement powerful AI capabilities in your applications.
## What are Built-in Models?
Built-in models in KaibanJS are pre-integrated language models that require minimal setup to use. These models are ready to go with just a few lines of configuration, making it easy to get started with AI-powered agents.
## Available Built-in Models
KaibanJS currently supports the following built-in models:
1. **OpenAI**: Access to state-of-the-art models like GPT-4 and GPT-3.5-turbo.
2. **Anthropic**: Integration with Claude models, known for their strong performance and safety features.
3. **Google**: Utilize Google's Gemini models, offering cutting-edge natural language processing capabilities.
4. **Mistral**: Leverage Mistral AI's efficient language models, designed for various NLP tasks.
## Key Benefits
- **Easy Setup**: Minimal configuration required to start using these models.
- **Consistent API**: Uniform interface across different model providers.
- **Automatic Updates**: Stay current with the latest model versions and features.
## Getting Started
To use a built-in model, simply specify the provider and model name in your agent's `llmConfig`:
```javascript
const agent = new Agent({
name: 'AI Assistant',
role: 'Helper',
llmConfig: {
provider: 'openai', // or 'anthropic', 'google', 'mistral'
model: 'gpt-4', // specific model name
}
});
```
Explore the individual model pages for detailed setup instructions and advanced configuration options.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/llms-docs/built-in-models/02-OpenAI.md
//--------------------------------------------
// File: ./src/llms-docs/built-in-models/02-OpenAI.md
//--------------------------------------------
---
title: OpenAI
description: Guide to using OpenAI's language models in KaibanJS
---
> KaibanJS seamlessly integrates with OpenAI's powerful language models, allowing you to leverage state-of-the-art AI capabilities in your applications. This integration supports various OpenAI models, including GPT-4o and GPT-4o-mini.
## Supported Models
KaibanJS supports all of OpenAI's chat models available through the OpenAI API. These chat models are designed for natural language conversations and are ideal for a wide range of applications. The list of supported models is dynamic and may change as OpenAI introduces new chat models or retires older ones.
Here are some examples of popular OpenAI chat models:
- GPT-4o
- GPT-4o-mini
- GPT-4
- gpt-3.5-turbo
- etc
For a comprehensive list of available models and their capabilities, please refer to the [official OpenAI documentation](https://platform.openai.com/docs/models).
## Configuration
To use an OpenAI model in your KaibanJS agent, configure the `llmConfig` property as follows:
```javascript
const agent = new Agent({
name: 'OpenAI Agent',
role: 'Assistant',
llmConfig: {
provider: 'openai',
model: 'gpt-4o', // or 'gpt-4o-mini', etc.
}
});
```
## API Key Setup
To use OpenAI models, you need to provide an API key. There are two recommended ways to do this:
1. **Agent Configuration**: Specify the API key in the `llmConfig` when creating an agent:
```javascript
const agent = new Agent({
name: 'OpenAI Agent',
role: 'Assistant',
llmConfig: {
provider: 'openai',
model: 'gpt-4o', // or 'gpt-4o-mini', etc.
apiKey: 'your-api-key-here'
}
});
```
2. **Team Configuration**: Provide the API key in the `env` property when creating a team:
```javascript
const team = new Team({
name: 'OpenAI Team',
agents: [agent],
env: {
OPENAI_API_KEY: 'your-api-key-here'
}
});
```
:::warning[API Key Security]
Always use environment variables for API keys instead of hardcoding them. This enhances security and simplifies key management across different environments.
**Example:**
```javascript
apiKey: process.env.YOUR_API_KEY
```
Never commit API keys to version control. Use a `.env` file or a secure secrets management system for sensitive information.
Please refer to [API Keys Management](/how-to/API%20Key%20Management) to learn more about handling API Keys safely.
:::
## Advanced Configuration and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means we're compatible with all the parameters that Langchain's OpenAI integration supports. This provides you with extensive flexibility in configuring your language models.
For more control over the model's behavior, you can pass additional parameters in the `llmConfig`. These parameters correspond to those supported by [Langchain's OpenAI integration](https://js.langchain.com/docs/integrations/chat/openai/).
Here's an example of how to use advanced configuration options:
```javascript
const agent = new Agent({
name: 'Advanced OpenAI Agent',
role: 'Assistant',
llmConfig: {
provider: 'openai',
model: 'gpt-4',
temperature: 0.7,
// Any other Langchain-supported parameters...
}
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain OpenAI Integration Documentation](https://js.langchain.com/docs/integrations/chat/openai/)
## Best Practices
1. **Model Selection**: Choose the appropriate model based on your task complexity and required capabilities.
2. **Cost Management**: Be mindful of token usage, especially with more powerful models like GPT-4.
3. **Error Handling**: Implement proper error handling to manage API rate limits and other potential issues.
## Limitations
- Token limits vary by model. Ensure your inputs don't exceed these limits.
- Costs can accumulate quickly with heavy usage. Monitor your usage closely.
## Further Resources
- [OpenAI Models Overview](https://platform.openai.com/docs/models)
- [Langchain OpenAI Integration Documentation](https://js.langchain.com/docs/integrations/chat/openai/)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/llms-docs/built-in-models/03-Anthropic.md
//--------------------------------------------
// File: ./src/llms-docs/built-in-models/03-Anthropic.md
//--------------------------------------------
---
title: Anthropic
description: Guide to using Anthropic's language models in KaibanJS
---
> KaibanJS seamlessly integrates with Anthropic's powerful language models, allowing you to leverage advanced AI capabilities in your applications. This integration supports various Anthropic models, including Claude 3 Opus, Claude 3 Sonnet, and Claude 3 Haiku.
## Supported Models
KaibanJS supports all of Anthropic's chat models available through the Anthropic API. These models are designed for natural language conversations and are ideal for a wide range of applications. The list of supported models is dynamic and may change as Anthropic introduces new models or retires older ones.
Here are some examples of popular Anthropic models:
- claude-3-5-sonnet-20240620
- claude-3-opus-20240229
- claude-3-haiku-20240307
For a comprehensive list of available models and their capabilities, please refer to the [official Anthropic documentation](https://docs.anthropic.com/en/docs/about-claude/models).
## Configuration
To use an Anthropic model in your KaibanJS agent, configure the `llmConfig` property as follows:
```javascript
const agent = new Agent({
name: 'Anthropic Agent',
role: 'Assistant',
llmConfig: {
provider: 'anthropic',
model: 'claude-3-5-sonnet-20240620', // or any other Anthropic model
apiKey: 'your-api-key-here'
}
});
```
## API Key Setup
To use Anthropic models, you need to provide an API key. There are two recommended ways to do this:
1. **Agent Configuration**: Specify the API key in the `llmConfig` when creating an agent:
```javascript
const agent = new Agent({
name: 'Anthropic Agent',
role: 'Assistant',
llmConfig: {
provider: 'anthropic',
model: 'claude-3-opus-20240229',
apiKey: 'your-api-key-here'
}
});
```
2. **Team Configuration**: Provide the API key in the `env` property when creating a team:
```javascript
const team = new Team({
name: 'Anthropic Team',
agents: [agent],
env: {
ANTHROPIC_API_KEY: 'your-api-key-here'
}
});
```
:::warning[CORS Issues in Browser]
When using Anthropic's API directly in browser environments, you may encounter CORS errors. To resolve this, you have two options:
1. **Use the Kaiban LLM Proxy**: Deploy our ready-to-use proxy solution:
- Fork and deploy [kaiban-llm-proxy](https://github.com/kaiban-ai/kaiban-llm-proxy)
- Add the proxy URL to your agent configuration using `apiBaseUrl`
2. **Custom Integration**: Implement Anthropic as a custom integration using the latest LangchainJS integration
Example with proxy:
```javascript
const agent = new Agent({
name: 'Anthropic Agent',
role: 'Assistant',
llmConfig: {
provider: 'anthropic',
model: 'claude-3-5-sonnet-20240620',
apiKey: 'your-api-key-here',
apiBaseUrl: 'https://your-proxy-url.com/proxy/anthropic'
}
});
```
:::
:::warning[API Key Security]
Always use environment variables for API keys instead of hardcoding them. This enhances security and simplifies key management across different environments.
**Example:**
```javascript
apiKey: process.env.YOUR_API_KEY
```
Never commit API keys to version control. Use a `.env` file or a secure secrets management system for sensitive information.
Please refer to [API Keys Management](/how-to/API%20Key%20Management) to learn more about handling API Keys safely.
:::
## Advanced Configuration and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means we're compatible with all the parameters that Langchain's Anthropic integration supports. This provides you with extensive flexibility in configuring your language models.
For more control over the model's behavior, you can pass additional parameters in the `llmConfig`. These parameters correspond to those supported by [Langchain's Anthropic integration](https://js.langchain.com/docs/integrations/chat/anthropic/).
Here's an example of how to use advanced configuration options:
```javascript
const agent = new Agent({
name: 'Advanced Anthropic Agent',
role: 'Assistant',
llmConfig: {
provider: 'anthropic',
model: 'claude-3-opus-20240229',
temperature: 0.7,
maxTokens: 1000,
// Any other Langchain-supported parameters...
}
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Anthropic Integration Documentation](https://js.langchain.com/docs/integrations/chat/anthropic/)
## Best Practices
1. **Model Selection**: Choose the appropriate model based on your task complexity and required capabilities. For example, use Claude 3 Opus for complex tasks, Claude 3 Sonnet for a balance of performance and efficiency, and Claude 3 Haiku for faster, simpler tasks.
2. **Cost Management**: Be mindful of token usage, especially with more powerful models like Claude 3 Opus.
3. **Error Handling**: Implement proper error handling to manage API rate limits and other potential issues.
## Limitations
- Token limits vary by model. Ensure your inputs don't exceed these limits.
- Costs can accumulate quickly with heavy usage. Monitor your usage closely.
## Further Resources
- [Anthropic Models Overview](https://docs.anthropic.com/en/docs/about-claude/models)
- [Langchain Anthropic Integration Documentation](https://js.langchain.com/docs/integrations/chat/anthropic/)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/built-in-models/04-Google.md
//--------------------------------------------
// File: ./src/llms-docs/built-in-models/04-Google.md
//--------------------------------------------
---
title: Google
description: Guide to using Google's Gemini language models in KaibanJS
---
> KaibanJS seamlessly integrates with Google's powerful Gemini language models, allowing you to leverage cutting-edge AI capabilities in your applications. This integration supports various Gemini models, designed for a wide range of natural language processing tasks.
## Supported Models
KaibanJS supports Google's Gemini models available through the Google AI API. These models are designed for versatile natural language understanding and generation tasks. The list of supported models may evolve as Google introduces new models or updates existing ones.
Currently supported Gemini models include:
- gemini-1.5-pro
- gemini-1.5-flash
For the most up-to-date information on available models and their capabilities, please refer to the [official Google AI documentation](https://ai.google.dev/models/gemini).
## Configuration
To use a Gemini model in your KaibanJS agent, configure the `llmConfig` property as follows:
```javascript
const agent = new Agent({
name: 'Gemini Agent',
role: 'Assistant',
llmConfig: {
provider: 'google',
model: 'gemini-1.5-pro', // or 'gemini-1.5-flash'
}
});
```
## API Key Setup
To use Gemini models, you need to provide an API key. There are two recommended ways to do this:
1. **Agent Configuration**: Specify the API key in the `llmConfig` when creating an agent:
```javascript
const agent = new Agent({
name: 'Gemini Agent',
role: 'Assistant',
llmConfig: {
provider: 'google',
model: 'gemini-1.5-pro',
apiKey: 'your-api-key-here'
}
});
```
2. **Team Configuration**: Provide the API key in the `env` property when creating a team:
```javascript
const team = new Team({
name: 'Gemini Team',
agents: [agent],
env: {
GOOGLE_API_KEY: 'your-api-key-here'
}
});
```
:::warning[API Key Security]
Always use environment variables for API keys instead of hardcoding them. This enhances security and simplifies key management across different environments.
**Example:**
```javascript
apiKey: process.env.YOUR_API_KEY
```
Never commit API keys to version control. Use a `.env` file or a secure secrets management system for sensitive information.
Please refer to [API Keys Management](/how-to/API%20Key%20Management) to learn more about handling API Keys safely.
:::
## Advanced Configuration and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means we're compatible with all the parameters that Langchain's Google Generative AI integration supports. This provides you with extensive flexibility in configuring your language models.
For more control over the model's behavior, you can pass additional parameters in the `llmConfig`. These parameters correspond to those supported by [Langchain's Google Generative AI integration](https://js.langchain.com/docs/integrations/chat/google_generativeai/).
Here's an example of how to use advanced configuration options:
```javascript
const agent = new Agent({
name: 'Advanced Gemini Agent',
role: 'Assistant',
llmConfig: {
provider: 'google',
model: 'gemini-1.5-pro',
temperature: 0.7
// Any other Langchain-supported parameters...
}
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Google Generative AI Integration Documentation](https://js.langchain.com/docs/integrations/chat/google_generativeai/)
## Best Practices
1. **Model Selection**: Choose the appropriate model based on your task requirements. Use 'gemini-pro' for text-based tasks and 'gemini-pro-vision' for multimodal tasks involving both text and images.
2. **Safety Settings**: Utilize safety settings to control the model's output based on your application's requirements.
3. **Error Handling**: Implement proper error handling to manage API rate limits and other potential issues.
## Limitations
- Token limits may vary. Ensure your inputs don't exceed these limits.
- Costs can accumulate with heavy usage. Monitor your usage closely.
- The Gemini API may have specific rate limits or usage quotas. Check the Google AI documentation for the most current information.
## Further Resources
- [Google AI Gemini API Documentation](https://ai.google.dev/docs)
- [Langchain Google Generative AI Integration Documentation](https://js.langchain.com/docs/integrations/chat/google_generativeai/)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/built-in-models/05-Mistral.md
//--------------------------------------------
// File: ./src/llms-docs/built-in-models/05-Mistral.md
//--------------------------------------------
---
title: Mistral
description: Guide to using Mistral AI's language models in KaibanJS
---
> KaibanJS seamlessly integrates with Mistral AI's powerful language models, allowing you to leverage advanced AI capabilities in your applications. This integration supports various Mistral models, designed for a wide range of natural language processing tasks.
## Supported Models
KaibanJS supports Mistral AI's models available through the Mistral AI API. These models are designed for versatile natural language understanding and generation tasks. The list of supported models may evolve as Mistral AI introduces new models or updates existing ones.
Currently supported Mistral models include:
- mistral-tiny
- mistral-small
- mistral-medium
- mistral-large-latest
For the most up-to-date information on available models and their capabilities, please refer to the [official Mistral AI documentation](https://docs.mistral.ai/getting-started/models/).
## Configuration
To use a Mistral model in your KaibanJS agent, configure the `llmConfig` property as follows:
```javascript
const agent = new Agent({
name: 'Mistral Agent',
role: 'Assistant',
llmConfig: {
provider: 'mistral',
model: 'mistral-large-latest', // or any other Mistral model
}
});
```
## API Key Setup
To use Mistral models, you need to provide an API key. There are two recommended ways to do this:
1. **Agent Configuration**: Specify the API key in the `llmConfig` when creating an agent:
```javascript
const agent = new Agent({
name: 'Mistral Agent',
role: 'Assistant',
llmConfig: {
provider: 'mistral',
model: 'mistral-large-latest',
apiKey: 'your-api-key-here'
}
});
```
2. **Team Configuration**: Provide the API key in the `env` property when creating a team:
```javascript
const team = new Team({
name: 'Mistral Team',
agents: [agent],
env: {
MISTRAL_API_KEY: 'your-api-key-here'
}
});
```
:::warning[API Key Security]
Always use environment variables for API keys instead of hardcoding them. This enhances security and simplifies key management across different environments.
**Example:**
```javascript
apiKey: process.env.YOUR_API_KEY
```
Never commit API keys to version control. Use a `.env` file or a secure secrets management system for sensitive information.
Please refer to [API Keys Management](/how-to/API%20Key%20Management) to learn more about handling API Keys safely.
:::
## Advanced Configuration and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means we're compatible with all the parameters that Langchain's Mistral AI integration supports. This provides you with extensive flexibility in configuring your language models.
For more control over the model's behavior, you can pass additional parameters in the `llmConfig`. These parameters correspond to those supported by [Langchain's Mistral AI integration](https://js.langchain.com/docs/integrations/chat/mistral/).
Here's an example of how to use advanced configuration options:
```javascript
const agent = new Agent({
name: 'Advanced Mistral Agent',
role: 'Assistant',
llmConfig: {
provider: 'mistral',
model: 'mistral-large-latest',
temperature: 0,
maxRetries: 2,
// Any other Langchain-supported parameters...
}
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Mistral AI Integration Documentation](https://js.langchain.com/docs/integrations/chat/mistral/)
## Best Practices
1. **Model Selection**: Choose the appropriate model based on your task complexity and required capabilities. For example, use `mistral-large-latest` for more complex tasks and `mistral-tiny` for simpler, faster responses.
2. **Cost Management**: Be mindful of token usage, especially with larger models.
3. **Error Handling**: Implement proper error handling to manage API rate limits and other potential issues.
## Limitations
- Token limits may vary by model. Ensure your inputs don't exceed these limits.
- Costs can accumulate with heavy usage. Monitor your usage closely.
- The Mistral AI API may have specific rate limits or usage quotas. Check the Mistral AI documentation for the most current information.
## Further Resources
- [Mistral AI Models Documentation](https://docs.mistral.ai/getting-started/models/)
- [Langchain Mistral AI Integration Documentation](https://js.langchain.com/docs/integrations/chat/mistral/)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/01-Overview.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/01-Overview.md
//--------------------------------------------
---
title: Overview
description: An introduction to integrating additional Language Models with KaibanJS
---
> KaibanJS supports integration with a variety of additional LLM providers and services, allowing you to expand your AI capabilities beyond the built-in options.
## What are Custom Integrations?
Custom integrations in KaibanJS allow you to use language models that aren't pre-integrated into the framework. These integrations require some additional setup but offer greater flexibility and access to specialized models.
## Available Custom Integrations
KaibanJS supports custom integrations with:
1. **Ollama**: Run open-source models locally.
2. **Cohere**: Access Cohere's suite of language models.
3. **Azure OpenAI**: Use OpenAI models through Azure's cloud platform.
4. **Cloudflare**: Integrate with Cloudflare's AI services.
5. **Groq**: Utilize Groq's high-performance inference engines.
6. **Other Integrations**: Explore additional options for specialized needs.
## Key Benefits
- **Flexibility**: Choose from a wider range of model providers.
- **Local Deployment**: Options for running models on your own infrastructure.
- **Specialized Models**: Access to models optimized for specific tasks or industries.
## Getting Started
To use a custom integration, you'll typically need to import the specific LLM package and configure it before passing it to your agent:
```javascript
import { SomeLLM } from "some-llm-package";
const customLLM = new SomeLLM({
// LLM-specific configuration
});
const agent = new Agent({
name: 'Custom AI Assistant',
role: 'Specialized Helper',
llmInstance: customLLM
});
```
Explore the individual integration pages for detailed setup instructions and configuration options for each supported LLM.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/llms-docs/custom-integrations/02-Ollama.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/02-Ollama.md
//--------------------------------------------
---
title: Ollama
description: Guide to integrating Ollama models with KaibanJS
---
> KaibanJS allows you to integrate Ollama's powerful language models into your applications. This integration enables you to run various open-source models locally, providing flexibility and control over your AI capabilities.
## Overview
Ollama is a tool that allows you to run open-source large language models locally. By integrating Ollama with KaibanJS, you can leverage these models in your agents, enabling offline operation and customization of your AI assistants.
## Supported Models
Ollama supports a wide range of open-source models, including but not limited to:
- Llama 2 (7B, 13B, 70B)
- Code Llama (7B, 13B, 34B)
- Mistral (7B)
- Phi-2
- Falcon (7B, 40B)
- Orca 2
- Vicuna
- Etc
For the most up-to-date list of available models and their capabilities, please refer to the [official Ollama model library](https://ollama.com/library).
## Integration Steps
To use an Ollama model in your KaibanJS agent, follow these steps:
1. **Install Ollama**: First, ensure you have Ollama installed on your system. Follow the installation instructions on the [Ollama website](https://ollama.ai/).
2. **Install LangChain's Cora and Ollama Integration**: Install the necessary package:
```bash
npm i @langchain/core
npm i @langchain/ollama
```
3. **Import and Configure the Model**: In your KaibanJS project, import and configure the Ollama model:
```javascript
import { ChatOllama } from "@langchain/ollama";
const ollamaModel = new ChatOllama({
model: "llama3.1", // or any other model you've pulled with Ollama
temperature: 0.7,
maxRetries: 2,
// Other Langchain-supported parameters
});
```
4. **Create the Agent**: Use the configured Ollama model in your KaibanJS agent:
```javascript
const agent = new Agent({
name: 'Ollama Agent',
role: 'Assistant',
goal: 'Provide assistance using locally run open-source models.',
background: 'AI Assistant powered by Ollama',
llmInstance: ollamaModel
});
```
## Configuration Options and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means you can use all the parameters that Langchain's Ollama integration supports. This provides extensive flexibility in configuring your language models.
Here's an example of using advanced configuration options:
```javascript
import { ChatOllama } from "@langchain/ollama";
const ollamaModel = new ChatOllama({
model: "llama2",
temperature: 0.7,
maxRetries: 2,
baseUrl: "http://localhost:11434",
// Any other Langchain-supported parameters...
});
const agent = new Agent({
name: 'Advanced Ollama Agent',
role: 'Assistant',
goal: 'Provide advanced assistance using locally run open-source models.',
background: 'AI Assistant powered by Ollama with advanced configuration',
llmInstance: ollamaModel
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Ollama Integration Documentation](https://js.langchain.com/docs/integrations/chat/ollama/)
## Best Practices
1. **Model Selection**: Choose an appropriate model based on your task requirements and available system resources.
2. **Resource Management**: Be aware of your system's capabilities when running larger models locally.
3. **Updates**: Regularly update your Ollama installation to access the latest models and improvements.
4. **Experiment with Parameters**: Adjust temperature, top_p, and other parameters to fine-tune model output for your specific use case.
## Limitations
- Performance depends on your local hardware capabilities.
- Some larger models may require significant computational resources.
- Ensure you comply with the licensing terms of the open-source models you use.
## Further Resources
- [Ollama Official Website](https://ollama.ai/)
- [Ollama Model Library](https://ollama.com/library)
- [LangChain Ollama Integration Documentation](https://js.langchain.com/docs/integrations/chat/ollama/)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/03-Azure.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/03-Azure.md
//--------------------------------------------
---
title: Azure OpenAI
description: Guide to integrating Azure OpenAI models with KaibanJS
---
> KaibanJS allows you to integrate Azure OpenAI's powerful language models into your applications. This integration enables you to leverage OpenAI's models through Microsoft Azure's cloud platform, providing enterprise-grade security, compliance, and regional availability.
## Overview
Azure OpenAI Service provides API access to OpenAI's powerful language models like GPT-4, GPT-3.5-Turbo, and Embeddings model series. By integrating Azure OpenAI with KaibanJS, you can leverage these models in your agents while benefiting from Azure's scalability and security features.
## Supported Models
Azure OpenAI supports a range of OpenAI models, including:
- GPT-4 and GPT-4 Turbo
- GPT-3.5-Turbo
For the most up-to-date list of available models and their capabilities, please refer to the [official Azure OpenAI documentation](https://azure.microsoft.com/en-us/pricing/details/cognitive-services/openai-service/).
## Integration Steps
To use an Azure OpenAI model in your KaibanJS agent, follow these steps:
1. **Set up Azure OpenAI**: First, ensure you have an Azure account and have set up the Azure OpenAI service. Follow the instructions in the [Azure OpenAI documentation](https://learn.microsoft.com/en-us/azure/ai-services/openai/how-to/create-resource?pivots=web-portal).
2. **Install LangChain's OpenAI Integration**: Install the necessary package:
```bash
npm install @langchain/openai
```
3. **Import and Configure the Model**: In your KaibanJS project, import and configure the Azure OpenAI model:
```javascript
import { AzureChatOpenAI } from "@langchain/openai";
const azureOpenAIModel = new AzureChatOpenAI({
model: "gpt-4",
azureOpenAIApiKey: process.env.AZURE_OPENAI_API_KEY,
azureOpenAIApiInstanceName: process.env.AZURE_OPENAI_API_INSTANCE_NAME,
azureOpenAIApiDeploymentName: process.env.AZURE_OPENAI_API_DEPLOYMENT_NAME,
azureOpenAIApiVersion: process.env.AZURE_OPENAI_API_VERSION,
});
```
4. **Create the Agent**: Use the configured Azure OpenAI model in your KaibanJS agent:
```javascript
const agent = new Agent({
name: 'Azure OpenAI Agent',
role: 'Assistant',
goal: 'Provide assistance using Azure-hosted OpenAI models.',
background: 'AI Assistant powered by Azure OpenAI',
llmInstance: azureOpenAIModel
});
```
## Configuration Options and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means you can use all the parameters that Langchain's Azure OpenAI integration supports. This provides extensive flexibility in configuring your language models.
Here's an example of using advanced configuration options:
```javascript
import { AzureChatOpenAI } from "@langchain/openai";
const azureOpenAIModel = new AzureChatOpenAI({
model: "gpt-4",
azureOpenAIApiKey: process.env.AZURE_OPENAI_API_KEY,
azureOpenAIApiInstanceName: process.env.AZURE_OPENAI_API_INSTANCE_NAME,
azureOpenAIApiDeploymentName: process.env.AZURE_OPENAI_API_DEPLOYMENT_NAME,
azureOpenAIApiVersion: process.env.AZURE_OPENAI_API_VERSION,
temperature: 0,
maxTokens: undefined,
maxRetries: 2,
// Any other Langchain-supported parameters...
});
const agent = new Agent({
name: 'Advanced Azure OpenAI Agent',
role: 'Assistant',
goal: 'Provide advanced assistance using Azure-hosted OpenAI models.',
background: 'AI Assistant powered by Azure OpenAI with advanced configuration',
llmInstance: azureOpenAIModel
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Azure OpenAI Integration Documentation](https://js.langchain.com/docs/integrations/chat/azure)
## Best Practices
1. **Security**: Always use environment variables or a secure secret management system to store your Azure OpenAI API keys and other sensitive information.
2. **Model Selection**: Choose an appropriate model based on your task requirements and available resources.
3. **Monitoring**: Utilize Azure's monitoring and logging capabilities to track usage and performance.
4. **Cost Management**: Be aware of the pricing model and monitor your usage to manage costs effectively.
## Limitations
- Access to Azure OpenAI is currently limited and requires an application process.
- Some features or the latest models might be available on OpenAI before they are available on Azure OpenAI.
- Ensure compliance with Azure's usage policies and any applicable regulations in your region.
## Further Resources
- [Azure OpenAI Service Documentation](https://learn.microsoft.com/en-us/azure/ai-services/openai/)
- [Azure OpenAI Models Overview](https://learn.microsoft.com/en-us/azure/ai-services/openai/concepts/models)
- [LangChain Azure OpenAI Integration Documentation](https://js.langchain.com/docs/integrations/chat/azure)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/04-Cohere.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/04-Cohere.md
//--------------------------------------------
---
title: Cohere
description: Guide to integrating Cohere's language models with KaibanJS
---
> KaibanJS allows you to integrate Cohere's powerful language models into your applications. This integration enables you to leverage Cohere's state-of-the-art models for various natural language processing tasks.
## Overview
Cohere provides a range of powerful language models that can significantly enhance KaibanJS agents. By integrating Cohere with KaibanJS, you can create more capable and versatile AI agents for various tasks.
## Supported Models
Cohere offers several chat-type models, each optimized for specific use cases:
- Command-R-Plus-08-2024: Latest update of Command R+ (August 2024), best for complex RAG workflows and multi-step tool use
- Command-R-Plus-04-2024: High-quality instruction-following model with 128k context length
- Command-R-08-2024: Updated version of Command R (August 2024)
- Command-R-03-2024: Versatile model for complex tasks like code generation, RAG, and agents
- Etc
All these models have a 128k token context length and can generate up to 4k tokens of output. They are accessible through the Chat endpoint.
For the most up-to-date information on available models and their capabilities, please refer to the [official Cohere documentation](https://docs.cohere.com/docs/models).
## Integration Steps
To use a Cohere model in your KaibanJS agent, follow these steps:
1. **Sign up for Cohere**: First, ensure you have a Cohere account and API key. Sign up at [Cohere's website](https://cohere.com/).
2. **Install LangChain's Cohere Integration**: Install the necessary package:
```bash
npm install @langchain/cohere
```
3. **Import and Configure the Model**: In your KaibanJS project, import and configure the Cohere model:
```javascript
import { ChatCohere } from "@langchain/cohere";
const cohereModel = new ChatCohere({
model: "command-r-plus", // or any other Cohere model
apiKey: 'your-api-key'
});
```
4. **Create the Agent**: Use the configured Cohere model in your KaibanJS agent:
```javascript
const agent = new Agent({
name: 'Cohere Agent',
role: 'Assistant',
goal: 'Provide assistance using Cohere's language models.',
background: 'AI Assistant powered by Cohere',
llmInstance: cohereModel
});
```
## Configuration Options and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means you can use all the parameters that Langchain's Cohere integration supports. This provides extensive flexibility in configuring your language models.
Here's an example of using advanced configuration options:
```javascript
import { ChatCohere } from "@langchain/cohere";
const cohereModel = new ChatCohere({
model: "command-r-plus", // or any other Cohere model
apiKey: 'your-api-key'
temperature: 0,
maxRetries: 2,
// Any other Langchain-supported parameters...
});
const agent = new Agent({
name: 'Advanced Cohere Agent',
role: 'Assistant',
goal: 'Provide advanced assistance using Cohere's language models.',
background: 'AI Assistant powered by Cohere with advanced configuration',
llmInstance: cohereModel
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Cohere Integration Documentation](https://js.langchain.com/docs/integrations/chat/cohere)
## Best Practices
1. **Model Selection**: Choose the appropriate model based on your specific use case (e.g., Command for general tasks, Base for embeddings and similarity).
2. **API Key Security**: Always use environment variables or a secure secret management system to store your Cohere API key.
3. **Token Management**: Be mindful of token usage, especially when using the maxTokens parameter, to optimize costs and performance.
4. **Error Handling**: Implement proper error handling to manage API rate limits and other potential issues.
## Pricing and Limitations
Cohere offers different pricing tiers based on usage:
- Free Tier: Limited number of API calls per month
- Pay-as-you-go: Charged based on the number of tokens processed
- Enterprise: Custom pricing for high-volume users
For the most current pricing information, visit the [Cohere Pricing Page](https://cohere.com/pricing).
Keep in mind:
- API rate limits may apply depending on your plan.
- Some advanced features may require higher-tier plans.
## Further Resources
- [Cohere Official Website](https://cohere.com/)
- [Cohere API Documentation](https://docs.cohere.com/reference/about)
- [Langchain Cohere Integration Documentation](https://js.langchain.com/docs/integrations/chat/cohere)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/05-Groq.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/05-Groq.md
//--------------------------------------------
---
title: Groq
description: Guide to integrating Groq's language models with KaibanJS
---
> KaibanJS allows you to integrate Groq's high-performance language models into your applications. This integration enables you to leverage Groq's ultra-fast inference capabilities for various natural language processing tasks.
## Overview
Groq provides access to large language models (LLMs) with extremely low latency, making it ideal for applications that require real-time AI responses. By integrating Groq with KaibanJS, you can enhance your agents with rapid and efficient language processing capabilities.
## Supported Models
Groq offers access to several open-source LLMs, optimized for high-speed inference. Some of the supported models include:
- LLaMA 3.1 (7B, 70B)
- Mixtral 8x7B
- Gemma 7B
- Etc
For the most up-to-date information on available models and their capabilities, please refer to the [official Groq documentation](https://console.groq.com/docs/models).
## Integration Steps
To use a Groq model in your KaibanJS agent, follow these steps:
1. **Sign up for Groq**: First, ensure you have a Groq account and API key. Sign up at [Groq's website](https://www.groq.com/).
2. **Install LangChain's Groq Integration**: Install the necessary package:
```bash
npm install @langchain/groq
```
3. **Import and Configure the Model**: In your KaibanJS project, import and configure the Groq model:
```javascript
import { ChatGroq } from "@langchain/groq";
const groqModel = new ChatGroq({
model: "llama2-70b-4096",
apiKey: 'your-api-key',
});
```
4. **Create the Agent**: Use the configured Groq model in your KaibanJS agent:
```javascript
const agent = new Agent({
name: 'Groq Agent',
role: 'Assistant',
goal: 'Provide rapid assistance using Groq's high-performance language models.',
background: 'AI Assistant powered by Groq',
llmInstance: groqModel
});
```
## Configuration Options and Langchain Compatibility
KaibanJS uses Langchain under the hood, which means you can use all the parameters that Langchain's Groq integration supports. This provides extensive flexibility in configuring your language models.
Here's an example of using advanced configuration options:
```javascript
import { ChatGroq } from "@langchain/groq";
const groqModel = new ChatGroq({
model: "llama2-70b-4096",
apiKey: 'your-api-key',
temperature: 0,
maxTokens: undefined,
maxRetries: 30,
// Any other Langchain-supported parameters...
});
const agent = new Agent({
name: 'Advanced Groq Agent',
role: 'Assistant',
goal: 'Provide advanced and rapid assistance using Groq's language models.',
background: 'AI Assistant powered by Groq with advanced configuration',
llmInstance: groqModel
});
```
For a comprehensive list of available parameters and advanced configuration options, please refer to the official Langchain documentation:
[Langchain Groq Integration Documentation](https://js.langchain.com/docs/integrations/chat/groq)
## Best Practices
1. **Model Selection**: Choose the appropriate model based on your specific use case and performance requirements.
2. **API Key Security**: Always use environment variables or a secure secret management system to store your Groq API key.
3. **Error Handling**: Implement proper error handling to manage API rate limits and other potential issues.
4. **Latency Optimization**: Leverage Groq's low-latency capabilities by designing your application to take advantage of rapid response times.
## Pricing and Limitations
Groq offers different pricing tiers based on usage:
- Free Tier: Limited number of API calls
- Pay-as-you-go: Charged based on the number of tokens processed
- Enterprise: Custom pricing for high-volume users
For the most current pricing information, visit the [Groq Pricing Page](https://groq.com/pricing/).
Keep in mind:
- API rate limits may apply depending on your plan.
- Pricing may vary based on the specific model and number of tokens processed.
## Further Resources
- [Groq Official Website](https://groq.com/)
- [Groq API Documentation](https://console.groq.com/docs/quickstart)
- [Langchain Groq Integration Documentation](https://js.langchain.com/docs/integrations/chat/groq)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/06-OpenRouter.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/06-OpenRouter.md
//--------------------------------------------
---
title: OpenRouter
description: Guide to integrating OpenRouter's unified AI model gateway with KaibanJS
---
# OpenRouter
> KaibanJS allows you to integrate OpenRouter's unified API gateway into your applications. This integration enables you to access multiple AI models from different providers through a single endpoint, simplifying model management and experimentation.
## Overview
OpenRouter is a unified API gateway that provides access to multiple AI models through a single endpoint. This integration allows KaibanJS users to easily access various AI models from different providers without managing multiple API keys or endpoints.
## Benefits
- Access to multiple AI models through a single API endpoint
- Simplified model switching and testing
- Consistent API interface across different model providers
- Cost-effective access to various AI models
- No need to manage multiple API keys for different providers
## Configuration
To use OpenRouter with KaibanJS, you'll need to:
1. Sign up for an account at [OpenRouter](https://openrouter.ai/)
2. Get your API key from the OpenRouter dashboard
3. Configure your agent with OpenRouter settings
Here's how to configure an agent to use OpenRouter:
```javascript
const profileAnalyst = new Agent({
name: 'Mary',
role: 'Profile Analyst',
goal: 'Extract structured information from conversational user input.',
background: 'Data Processor',
tools: [],
llmConfig: {
provider: "openai", // Keep this as "openai" since OpenRouter uses OpenAI-compatible endpoint
model: "meta-llama/llama-3.1-8b-instruct:free", // Use the exact model name from OpenRouter
apiBaseUrl: "https://openrouter.ai/api/v1",
apiKey: process.env.OPENROUTER_API_KEY // Use environment variable for security
}
});
```
## Environment Variables
It's recommended to use environment variables for your API key. Add this to your `.env` file:
```bash
OPENROUTER_API_KEY=your_api_key_here
```
## Available Models
OpenRouter provides access to various models from different providers. Here are some examples:
- `meta-llama/llama-3.1-8b-instruct:free`
- `anthropic/claude-2`
- `google/palm-2`
- `meta-llama/codellama-34b`
- And many more...
Visit the [OpenRouter models page](https://openrouter.ai/models) for a complete list of available models and their capabilities.
## Best Practices
1. **API Key Security**
- Always use environment variables for API keys
- Never commit API keys to version control
2. **Model Selection**
- Choose models based on your specific use case
- Consider the cost and performance trade-offs
- Test different models to find the best fit
3. **Error Handling**
- Implement proper error handling for API calls
- Have fallback models configured when possible
## Troubleshooting
If you encounter issues:
1. Verify your API key is correct
2. Check if the selected model is available in your OpenRouter plan
3. Ensure your API base URL is correct
4. Verify your network connection and firewall settings
For more help, visit the [OpenRouter documentation](https://openrouter.ai/docs) or the [KaibanJS community](https://github.com/kaibanjs/kaiban/discussions).
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/07-LM-Studio.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/07-LM-Studio.md
//--------------------------------------------
---
title: LM Studio
description: Guide to integrating LM Studio's local LLM server with KaibanJS
---
# LM Studio
> KaibanJS allows you to integrate LM Studio's local LLM server into your applications. This integration enables you to run AI models locally on your machine, providing a self-hosted alternative to cloud-based LLM services.
## Overview
LM Studio is a desktop application that allows you to run Large Language Models locally on your computer. By integrating LM Studio with KaibanJS, you can create AI agents that operate completely offline using your local computing resources.
## Prerequisites
1. Download and install [LM Studio](https://lmstudio.ai/) on your machine
2. Download and set up your desired model in LM Studio
3. Start the local server in LM Studio with CORS enabled
## Configuration
To use LM Studio with KaibanJS, configure your agent with the local server endpoint:
```javascript
const localAssistant = new Agent({
name: 'LocalAssistant',
role: 'General Assistant',
goal: 'Help users with various tasks using local LLM',
background: 'Local AI Assistant',
tools: [],
llmConfig: {
provider: "openai", // Keep this as "openai" since LM Studio uses OpenAI-compatible endpoint
model: "local-model", // Your local model name
apiBaseUrl: "http://localhost:1234/v1", // Default LM Studio server URL
apiKey: "not-needed" // LM Studio doesn't require an API key
}
});
```
## Server Configuration
1. In LM Studio, load your desired model
2. Go to the "Server" tab
3. Enable CORS in the server settings
4. Click "Start Server"
## Best Practices
1. **Model Selection**
- Choose models that fit your hardware capabilities
- Consider model size vs performance trade-offs
- Test different models locally before deployment
2. **Server Management**
- Ensure the LM Studio server is running before making requests
- Monitor system resources (RAM, CPU usage)
- Configure appropriate timeout values for longer inference times
3. **Error Handling**
- Implement connection error handling
- Add fallback options for server unavailability
- Monitor model loading status
## Troubleshooting
If you encounter issues:
1. Verify the LM Studio server is running
2. Check if CORS is enabled in LM Studio server settings
3. Confirm the correct local URL is configured
4. Ensure the model is properly loaded in LM Studio
5. Monitor system resources for potential bottlenecks
## Example Usage
Here's a complete example of using LM Studio with KaibanJS:
```javascript
import { Agent } from 'kaibanjs';
// Create an agent with LM Studio configuration
const assistant = new Agent({
name: 'LocalAssistant',
role: 'General Assistant',
goal: 'Help users with various tasks',
background: 'Local AI Assistant',
tools: [],
llmConfig: {
provider: "openai",
model: "meta-llama/llama-3.1-8b-instruct", // Example model name
apiBaseUrl: "http://localhost:1234/v1",
apiKey: "not-needed"
}
});
// Use the agent
try {
const response = await assistant.chat("Tell me about climate change");
console.log(response);
} catch (error) {
console.error("Error connecting to LM Studio:", error);
}
```
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/llms-docs/custom-integrations/08-Other Integrations.md
//--------------------------------------------
// File: ./src/llms-docs/custom-integrations/08-Other Integrations.md
//--------------------------------------------
---
title: Other LLM Integrations
description: Overview of additional language model integrations available through LangChain in KaibanJS
---
> KaibanJS, through its integration with LangChain, supports a wide variety of language models beyond the main providers. This section provides an overview of additional LLM integrations you can use with your KaibanJS agents.
## Available Integrations
KaibanJS supports the following additional language model integrations through LangChain:
1. [**Alibaba Tongyi**](https://js.langchain.com/docs/integrations/chat/alibaba_tongyi): Supports the Alibaba qwen family of models.
2. [**Arcjet Redact**](https://js.langchain.com/docs/integrations/chat/arcjet_redact): Allows redaction of sensitive information.
3. [**Baidu Qianfan**](https://js.langchain.com/docs/integrations/chat/baidu_qianfan): Provides access to Baidu's language models.
4. [**Deep Infra**](https://js.langchain.com/docs/integrations/chat/deep_infra): Offers hosted language models.
5. [**Fireworks**](https://js.langchain.com/docs/integrations/chat/fireworks): AI inference platform for running large language models.
6. [**Friendli**](https://js.langchain.com/docs/integrations/chat/friendli): Enhances AI application performance and optimizes cost savings.
7. [**Llama CPP**](https://js.langchain.com/docs/integrations/chat/llama_cpp): (Node.js only) Enables use of Llama models.
8. [**Minimax**](https://js.langchain.com/docs/integrations/chat/minimax): Chinese startup providing natural language processing services.
9. [**Moonshot**](https://js.langchain.com/docs/integrations/chat/moonshot): Supports the Moonshot AI family of models.
10. [**PremAI**](https://js.langchain.com/docs/integrations/chat/premai): Offers access to PremAI models.
11. [**Tencent Hunyuan**](https://js.langchain.com/docs/integrations/chat/tencent_hunyuan): Supports the Tencent Hunyuan family of models.
12. [**Together AI**](https://js.langchain.com/docs/integrations/chat/together_ai): Provides an API to query 50+ open-source models.
13. [**WebLLM**](https://js.langchain.com/docs/integrations/chat/web_llm): (Web environments only) Enables browser-based LLM usage.
14. [**YandexGPT**](https://js.langchain.com/docs/integrations/chat/yandex): Supports calling YandexGPT chat models.
15. [**ZhipuAI**](https://js.langchain.com/docs/integrations/chat/zhipu_ai): Supports the Zhipu AI family of models.
## Integration Process
The general process for integrating these models with KaibanJS is similar to other custom integrations:
1. Install the necessary LangChain package for the specific integration.
2. Import the appropriate chat model class from LangChain.
3. Configure the model with the required parameters.
4. Use the configured model instance in your KaibanJS agent.
Here's a generic example of how you might integrate one of these models:
```javascript
import { SomeSpecificChatModel } from "@langchain/some-specific-package";
const customModel = new SomeSpecificChatModel({
// Model-specific configuration options
apiKey: process.env.SOME_API_KEY,
// Other necessary parameters...
});
const agent = new Agent({
name: 'Custom Model Agent',
role: 'Assistant',
goal: 'Provide assistance using a custom language model.',
background: 'AI Assistant powered by a specific LLM integration',
llmInstance: customModel
});
```
## Features and Compatibility
Different integrations offer varying levels of support for advanced features. Here's a general overview:
- **Streaming**: Most integrations support streaming responses.
- **JSON Mode**: Some integrations support structured JSON outputs.
- **Tool Calling**: Many integrations support function/tool calling capabilities.
- **Multimodal**: Some integrations support processing multiple types of data (text, images, etc.).
Refer to the specific LangChain documentation for each integration to understand its exact capabilities and configuration options.
## Best Practices
1. **Documentation**: Always refer to the latest LangChain documentation for the most up-to-date integration instructions.
2. **API Keys**: Securely manage API keys and other sensitive information using environment variables.
3. **Error Handling**: Implement robust error handling, as different integrations may have unique error patterns.
4. **Testing**: Thoroughly test the integration, especially when using less common or region-specific models.
## Limitations
- Some integrations may have limited documentation or community support.
- Certain integrations might be region-specific or have unique licensing requirements.
- Performance and capabilities can vary significantly between different integrations.
## Further Resources
- [LangChain Chat Models Documentation](https://js.langchain.com/docs/integrations/chat/)
- [LangChain GitHub Repository](https://github.com/langchain-ai/langchainjs)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/01-Overview.md
//--------------------------------------------
// File: ./src/tools-docs/01-Overview.md
//--------------------------------------------
---
title: Overview
description: An introduction to KaibanJS tools, including pre-integrated LangChain tools and custom tool development, enhancing AI agent capabilities for various tasks and integrations.
---
Welcome to the Tools Documentation for KaibanJS, where we guide you through the powerful capabilities that tools add to your AI agents. This section is designed to help you understand and utilize a diverse array of tools, ranging from internet searches to complex data analysis and automation tasks.
## What is a Tool?
> A Tool is a skill or function that agents can utilize to perform various actions:
>
> - Search on the Internet
> - Calculate data or predictions
> - Automate data entry tasks
>
## Understanding the Tool Sections
KaibanJS enhances the functionality of your agents through two primary tool categories:
- **[KaibanJS Tools](/category/kaibanjs-tools)**
- **[LangChain Tools](/category/langchain-tools)**
- **[Custom Tools](/category/custom-tools)**
Both sections are accessible through the sidebar/menu, where you can explore detailed documentation and resources.
### KaibanJS Tools
KaibanJS Tools are pre-integrated tools that are ready to use out of the box. We've tested and verified a subset to work seamlessly with KaibanJS, which you'll find listed in the sidebar.
### LangChain Tools
Developed and maintained by the [LangChain team](https://langchain.com/), they're ready to use out of the box. We've tested and verified a subset to work seamlessly with KaibanJS, which you'll find listed in the sidebar.
While LangChain offers many [more tools](https://js.langchain.com/v0.2/docs/integrations/tools/), we haven't tested them all yet. That said, we're happy to add more to the list, so please let us know which ones you'd like to see.
### Custom Tools
This section is for developers who want to create tools tailored to their specific needs or projects. It provides resources for building and integrating unique tools that go beyond the standard LangChain offerings:
- **Custom Tool Tutorial:** A step-by-step guide on how to create your own custom tool for KaibanJS.
- **Example Tools:** Showcases of custom tools to inspire and guide your development process.
JavaScript developers can leverage NPM's vast resources to create custom tools, extending KaibanJS's capabilities and integrating with numerous libraries and services.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/tools-docs/custom-tools/02-Create a Custom Tool.md
//--------------------------------------------
// File: ./src/tools-docs/custom-tools/02-Create a Custom Tool.md
//--------------------------------------------
---
title: Create a Custom Tool
description: Learn how to create and integrate custom tools for Kaiban agents, extending their capabilities with external APIs, services, or npm utilities.
---
# Create a Custom Tool
This tutorial will guide you through the process of creating a custom tool for use with Kaiban agents. Custom tools allow you to extend the capabilities of your AI agents by integrating external APIs, services, or npm utilities.
## Introduction
Custom tools in Kaiban are based on the LangChain `Tool` class and allow you to define specific functionalities that your agents can use. By creating custom tools, you can give your agents access to a wide range of capabilities, from web searches to complex computations.
## How Tools Work with Agents and LLMs
Understanding the interaction between tools, agents, and Language Models (LLMs) is crucial:
1. The agent, guided by the LLM, identifies a need for specific information or action.
2. The agent selects the appropriate tool based on its description and the current task.
3. The LLM generates the necessary input for the tool.
4. The agent calls the tool's `_call` method with this input.
5. The tool processes the input, performs its specific function (e.g., API call, computation), and returns the result.
6. The agent receives the tool's output and passes it back to the LLM.
7. The LLM interprets the result and decides on the next action or provides a response.
This process allows agents to leverage specialized functionalities while the LLM handles the high-level reasoning and decision-making.
## Prerequisites
Before you begin, make sure you have:
1. A basic understanding of JavaScript and async/await syntax.
2. Kaiban and LangChain libraries installed in your project.
3. Access to the API or service you want to integrate (if applicable).
## Step-by-Step Guide
### Step 1: Import Required Dependencies
Start by importing the necessary classes and libraries:
```javascript
import { Tool } from "@langchain/core/tools";
import { z } from "zod";
```
The `Tool` class from LangChain provides a standardized interface for creating custom tools. It ensures that your tool can be seamlessly integrated with Kaiban agents and LLMs. The `Tool` class handles the interaction between the agent and your custom functionality, making it easier to extend your agents' capabilities.
`Zod` is a TypeScript-first schema declaration and validation library. In the context of custom tools, Zod is used to:
1. Define the expected structure of the input that your tool will receive.
2. Validate the input at runtime, ensuring that your tool receives correctly formatted data.
3. Provide clear error messages if the input doesn't match the expected schema.
Using Zod enhances the reliability and ease of use of your custom tools.
### Step 2: Define Your Custom Tool Class
Create a new class that extends the `Tool` class:
```javascript
export class CustomTool extends Tool {
constructor(fields) {
super(fields);
// Initialize any required fields
this.apiKey = fields.apiKey;
// Set the tool's name and description
this.name = "custom_tool";
this.description = `Describe what your tool does and how it should be used.`;
// Define the input schema using zod
this.schema = z.object({
query: z.string().describe("Describe the expected input"),
});
}
async _call(input) {
// Implement the core functionality of your tool here
// This method will be called when the agent uses the tool
// Process the input and return the result
}
}
```
### Step 3: Implement the `_call` Method
The `_call` method is where you implement the main functionality of your tool. This method should:
1. Process the input
2. Make any necessary API calls or perform computations
3. Return the result
Here's an example:
```javascript
async _call(input) {
const url = 'https://api.example.com/endpoint';
const body = JSON.stringify({ query: input.query });
const res = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Authorization': `Bearer ${this.apiKey}`,
},
body: body
});
return res.json();
}
```
### Step 4: Use Your Custom Tool with a Kaiban Agent
Once you've created your custom tool, you can use it with a Kaiban agent:
```javascript
import { Agent } from 'kaibanjs';
import { CustomTool } from './CustomTool';
const customTool = new CustomTool({
apiKey: "YOUR_API_KEY",
});
const agent = new Agent({
name: 'CustomAgent',
role: 'Specialized Task Performer',
goal: 'Utilize the custom tool to perform specific tasks.',
background: 'Expert in using specialized tools for task completion',
tools: [customTool]
});
// Use the agent in your Kaiban workflow
```
:::important
The key to creating a highly reliable tool is to minimize its responsibilities and provide a clear, concise description for the LLM. This approach allows the LLM to understand the tool's purpose and use it effectively.
:::
## Ideas for Custom Tools
You can create a wide variety of custom tools using npm packages or external APIs. Here are some ideas:
1. **Web Scraping Tool** (using Puppeteer):
- Scrape dynamic web content or take screenshots of web pages.
```javascript
import puppeteer from 'puppeteer';
class WebScraperTool extends Tool {
async _call(input) {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto(input.url);
const content = await page.content();
await browser.close();
return content;
}
}
```
2. **PDF Processing Tool** (using pdf-parse):
- Extract text from PDF files.
```javascript
import pdf from 'pdf-parse';
class PDFExtractorTool extends Tool {
async _call(input) {
const dataBuffer = await fs.promises.readFile(input.filePath);
const data = await pdf(dataBuffer);
return data.text;
}
}
```
3. **Image Analysis Tool** (using sharp):
- Analyze or manipulate images.
```javascript
import sharp from 'sharp';
class ImageAnalyzerTool extends Tool {
async _call(input) {
const metadata = await sharp(input.imagePath).metadata();
return metadata;
}
}
```
4. **Natural Language Processing Tool** (using natural):
- Perform NLP tasks like tokenization or sentiment analysis.
```javascript
import natural from 'natural';
class NLPTool extends Tool {
async _call(input) {
const tokenizer = new natural.WordTokenizer();
return tokenizer.tokenize(input.text);
}
}
```
5. **Database Query Tool** (using a database driver):
- Execute database queries and return results.
```javascript
import { MongoClient } from 'mongodb';
class DatabaseQueryTool extends Tool {
async _call(input) {
const client = new MongoClient(this.dbUrl);
await client.connect();
const db = client.db(this.dbName);
const result = await db.collection(input.collection).find(input.query).toArray();
await client.close();
return result;
}
}
```
These are just a few examples. The possibilities for custom tools are virtually limitless, allowing you to extend your agents' capabilities to suit your specific needs.
## Best Practices
1. **Clear Description**: Provide a clear and concise description of your tool's functionality to help the LLM understand when and how to use it.
2. **Input Validation**: Use zod to define a clear schema for your tool's input, ensuring that it receives the correct data types.
3. **Error Handling**: Implement robust error handling in your `_call` method to gracefully manage API errors or unexpected inputs.
4. **Modularity**: Design your tool to have a single, well-defined responsibility. This makes it easier to use and maintain.
5. **Documentation**: Comment your code and provide usage examples to make it easier for others (or yourself in the future) to understand and use your custom tool.
## Conclusion
Creating custom tools allows you to significantly extend the capabilities of your Kaiban agents. By following this tutorial and exploring various npm packages and APIs, you can create a wide range of specialized tools, enabling your agents to perform complex and diverse tasks.
:::info[We Love Feedback!]
Is there something unclear or quirky in this tutorial? Have a suggestion or spotted an issue? Help us improve by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). Your input is valuable!
:::
### ./src/tools-docs/custom-tools/04-Serper.md
//--------------------------------------------
// File: ./src/tools-docs/custom-tools/04-Serper.md
//--------------------------------------------
---
title: Serper Tool Example
description: Learn how to create a versatile search engine tool using Serper API that supports various search types, enhancing your Kaiban agents' capabilities, and how to use it in the Kaiban Board.
---
# Custom Serper Tool Example
This guide will show you how to create a custom Serper tool that can be used with Kaiban agents. [Serper](https://serper.dev/) is a powerful search engine API that supports a wide range of search types, including general search, image search, video search, and more.
By creating this custom tool, you can:
- Enable **Flexible Search Capabilities** for your agents, supporting various search types.
- Implement **Dynamic Query Handling** that automatically adjusts request parameters based on the specified search type.
:::tip[See It in Action!]
Want to see the Serper tool in action before diving into the code? We've got you covered! Click the link below to access a live demo of the tool running on the Kaiban Board.
[Try the Serper tool on the Kaiban Board](https://www.kaibanjs.com/share/cBjyih67gx7n7CKrsVmm)
:::
## Prerequisites
1. Sign up at [Serper](https://serper.dev/) to obtain an API key.
2. Ensure you have the necessary dependencies installed in your project.
## Creating the Custom Serper Tool
Here's how you can create a custom Serper tool for your Kaiban agents:
```javascript
import { Tool } from "@langchain/core/tools";
import { z } from "zod";
export class SerperTool extends Tool {
constructor(fields) {
super(fields);
this.apiKey = fields.apiKey;
this.params = fields.params;
this.type = fields.type || 'search';
this.name = "serper";
this.description = `A powerful search engine tool for retrieving real-time information and answering questions about current events. Input should be a search query.`;
// Set schema based on search type
this.schema = this.type === 'webpage'
? z.object({ url: z.string().describe("the URL to scrape") })
: z.object({ query: z.string().describe("the query to search for") });
}
async _call(input) {
let url = `https://google.serper.dev/${this.type}`;
let bodyData = this.type === 'webpage'
? { url: input.url }
: { q: input.query, ...this.params };
if (this.type === 'webpage') {
url = "https://scrape.serper.dev";
}
const options = {
method: "POST",
headers: {
"X-API-KEY": this.apiKey,
"Content-Type": "application/json",
},
body: JSON.stringify(bodyData),
};
const res = await fetch(url, options);
if (!res.ok) {
throw new Error(`Got ${res.status} error from serper: ${res.statusText}`);
}
return await res.json();
}
}
```
### Explanation of the Code
1. **LangChain Tool Specs**:
- We are using the `Tool` class from LangChain to create our custom tool. LangChain provides a framework for building tools that can be called by AI models. You can read more about LangChain Tool specifications [here](https://js.langchain.com/v0.2/docs/how_to/custom_tools/).
2. **Importing `zod`**:
- `import { z } from "zod";`
- `zod` is a TypeScript-first schema declaration and validation library. We use it to define and validate the input schema for our tool. This ensures that the input provided to the tool is in the correct format.
3. **Constructor**:
- The constructor initializes the tool with the provided fields, including the API key, parameters, and search type. It also sets the tool's name and description.
- The schema is dynamically set based on the type of search. For example, if the type is 'webpage', the schema expects a URL; otherwise, it expects a search query.
4. **_call Method**:
- The `_call` method is the core function that performs the search. It constructs the request URL and body based on the search type and sends a POST request to the Serper API.
- If the response is not OK, it throws an error with the status and status text.
- If the response is successful, it returns the JSON data.
:::important
The key to creating a highly reliable tool is to minimize its responsibilities and provide a clear, concise description for the LLM. This approach allows the LLM to understand the tool's purpose and use it effectively. In this example, the SerperTool has a single responsibility: performing searches. Its description clearly states its function, enabling the LLM to use it appropriately within the context of the agent's tasks.
:::
### How the Agent Uses the Tool
- When the agent needs to perform a search, it will call the `_call` method of the `SerperTool` with the parameters provided by the language model (LLM).
- The `_call` method processes the input, sends the request to the Serper API, and returns the response.
- The agent then uses this response to provide the necessary information or take further actions based on the search results.
## Using the Custom Serper Tool with Kaiban Agents
After creating the custom Serper tool, you can use it with your Kaiban agents as follows:
```javascript
import { Agent } from 'kaibanjs';
import { SerperTool } from './SerperTool'; // Import your custom tool
// Create an instance of the SerperTool
const serperTool = new SerperTool({
apiKey: "YOUR_SERPER_API_KEY",
type: "search" // or any other supported type
});
// Create a Kaiban agent with the Serper tool
const researchAgent = new Agent({
name: 'Alice',
role: 'Research Assistant',
goal: 'Conduct comprehensive online research on various topics.',
background: 'Experienced web researcher with advanced search skills.',
tools: [serperTool]
});
// Use the agent in your Kaiban workflow
// ... (rest of your Kaiban setup)
```
## Supported Search Types
The SerperTool supports various search types, which you can specify when creating an instance:
- `"search"` (default): General search queries
- `"images"`: Image search
- `"videos"`: Video search
- `"places"`: Location-based search
- `"maps"`: Map search
- `"news"`: News search
- `"shopping"`: Shopping search
- `"scholar"`: Academic publications search
- `"patents"`: Patent search
- `"webpage"`: Web page scraping (Beta)
## Using the Serper Tool in Kaiban Board
:::tip[Try it Out in the Playground!]
Before diving into the installation and coding, why not experiment directly with our interactive playground? [Try it now!](https://www.kaibanjs.com/share/cBjyih67gx7n7CKrsVmm)
:::
The Serper tool is also available for use directly in the [Kaiban Board](https://www.kaibanjs.com/playground), our interactive playground for building and testing AI workflows. Here's how you can use it:
1. Access the Kaiban Board at [https://www.kaibanjs.com/playground](https://www.kaibanjs.com/playground).
2. In the code editor, you can create an instance of the SerperTool without importing it:
```javascript
const tool = new SerperTool({
apiKey: "ENV_SERPER_API_KEY",
type: "search" // or any other supported type
});
const researchAgent = new Agent({
name: 'Alice',
role: 'Research Assistant',
goal: 'Conduct comprehensive online research on various topics.',
background: 'Experienced web researcher with advanced search skills.',
tools: [tool]
});
```
3. Use this agent in your Kaiban Board workflow, allowing it to perform searches and retrieve information as part of your AI process.
## Conclusion
By creating and using this custom Serper tool, you've significantly enhanced your Kaiban agents' ability to perform various types of online searches and web scraping tasks. Whether you're using it in your own code or in the Kaiban Board, this tool provides a flexible and powerful way to integrate real-time information retrieval into your AI workflows.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/custom-tools/05-WolframAlpha.md
//--------------------------------------------
// File: ./src/tools-docs/custom-tools/05-WolframAlpha.md
//--------------------------------------------
---
title: WolframAlpha Tool Example
description: Learn how to create a powerful computational tool using the WolframAlpha API that supports complex queries and scientific computations, enhancing your Kaiban agents' capabilities, and how to use it in the Kaiban Board.
---
# Custom WolframAlpha Tool Example
This guide will show you how to create a custom WolframAlpha tool that can be used with Kaiban agents. [WolframAlpha](https://www.wolframalpha.com/) is a powerful computational knowledge engine that provides detailed and accurate answers to complex queries across various scientific and mathematical domains.
By creating this custom tool, you can:
- Enable **Advanced Computational Capabilities** for your agents, supporting complex mathematical and scientific calculations.
- Implement **Data Analysis and Retrieval** from WolframAlpha's vast knowledge base.
- Ensure **Scientific Accuracy** in your agents' responses across various domains.
:::tip[See It in Action!]
Want to see the WolframAlpha tool in action before diving into the code? We've got you covered! Click the link below to access a live demo of the tool running on the Kaiban Board.
[Try the WolframAlpha tool on the Kaiban Board](https://www.kaibanjs.com/share/VyfPFnQHiKxtr2BUkY9F)
:::
## Prerequisites
1. Sign up at the [WolframAlpha Developer Portal](https://developer.wolframalpha.com/) to obtain an App ID.
2. Ensure you have the necessary dependencies installed in your project.
## Creating the Custom WolframAlpha Tool
Here's how you can create a custom WolframAlpha tool for your Kaiban agents:
```javascript
import { Tool } from "@langchain/core/tools";
import { z } from "zod";
export class WolframAlphaTool extends Tool {
constructor(fields) {
super(fields);
this.appId = fields.appId;
this.name = "wolfram_alpha";
this.description = `This tool leverages the computational intelligence of WolframAlpha to provide robust and detailed answers to complex queries. It allows users to perform advanced computations, data analysis, and retrieve scientifically accurate information across a wide range of domains, including mathematics, physics, engineering, astronomy, and more.`;
this.schema = z.object({
query: z.string().describe("the query to send to WolframAlpha"),
});
}
async _call(input) {
const url = '/proxy/wolframalpha';
const body = JSON.stringify({ query: input.query });
const res = await fetch(url, {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'X-APP-ID': this.appId,
},
body: body
});
return res.json();
}
}
```
### Explanation of the Code
1. **LangChain Tool Specs**:
- We are using the `Tool` class from LangChain to create our custom tool. LangChain provides a framework for building tools that can be called by AI models. You can read more about LangChain Tool specifications [here](https://js.langchain.com/v0.2/docs/how_to/custom_tools/).
2. **Importing `zod`**:
- `import { z } from "zod";`
- `zod` is a TypeScript-first schema declaration and validation library. We use it to define and validate the input schema for our tool. This ensures that the input provided to the tool is in the correct format.
3. **Constructor**:
- The constructor initializes the tool with the provided App ID, sets the tool's name and description, and defines the input schema.
4. **_call Method**:
- The `_call` method is the core function that performs the query. It sends a POST request to the WolframAlpha API proxy with the query and returns the JSON response.
:::important
The WolframAlphaTool is designed with a single, clear responsibility: performing complex computations and retrieving scientific data. Its concise description allows the LLM to understand its purpose and use it effectively within the context of the agent's tasks.
:::
### How the Agent Uses the Tool
- When the agent needs to perform a computation or retrieve scientific data, it will call the `_call` method of the `WolframAlphaTool` with the query provided by the language model (LLM).
- The `_call` method processes the input, sends the request to the WolframAlpha API, and returns the response.
- The agent then uses this response to provide accurate computational results, scientific information, or take further actions based on the retrieved data.
## Using the Custom WolframAlpha Tool with Kaiban Agents
After creating the custom WolframAlpha tool, you can use it with your Kaiban agents as follows:
```javascript
import { Agent } from 'kaibanjs';
import { WolframAlphaTool } from './WolframAlphaTool'; // Import your custom tool
// Create an instance of the WolframAlphaTool
const wolframTool = new WolframAlphaTool({
appId: "YOUR_WOLFRAM_APP_ID",
});
// Create a Kaiban agent with the WolframAlpha tool
const scientificAnalyst = new Agent({
name: 'Eve',
role: 'Scientific Analyst',
goal: 'Perform complex computations and provide accurate scientific data for research and educational purposes.',
background: 'Research Scientist with expertise in various scientific domains',
tools: [wolframTool]
});
// Use the agent in your Kaiban workflow
// ... (rest of your Kaiban setup)
```
## Using the WolframAlpha Tool in Kaiban Board
The WolframAlpha tool is also available for use directly in the [Kaiban Board](https://www.kaibanjs.com/playground), our interactive playground for building and testing AI workflows. Here's how you can use it:
1. Access the Kaiban Board at [https://www.kaibanjs.com/playground](https://www.kaibanjs.com/playground).
2. In the code editor, you can create an instance of the WolframAlphaTool without importing it:
```javascript
const tool = new WolframAlphaTool({
appId: "ENV_WOLFRAM_APP_ID",
});
const scientificAnalyst = new Agent({
name: 'Eve',
role: 'Scientific Analyst',
goal: 'Perform complex computations and provide accurate scientific data for research and educational purposes.',
background: 'Research Scientist with expertise in various scientific domains',
tools: [tool]
});
```
3. Use this agent in your Kaiban Board workflow, allowing it to perform complex computations and retrieve scientific data as part of your AI process.
## Conclusion
By creating and using this custom WolframAlpha tool, you've significantly enhanced your Kaiban agents' ability to perform advanced computations and retrieve accurate scientific data across various domains. Whether you're using it in your own code or in the Kaiban Board, this tool provides a powerful way to integrate computational intelligence into your AI workflows.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/custom-tools/06-Submit Your Tool.md
//--------------------------------------------
// File: ./src/tools-docs/custom-tools/06-Submit Your Tool.md
//--------------------------------------------
---
title: Submit Your Tool
description: Learn how to contribute your custom tool to the KaibanJS community and get support through our Discord channel.
---
# Submit Your Tool
Have you created a custom tool for KaibanJS that you think could benefit the community? We encourage you to share it! By submitting your tool, you can help expand the Javascript AI ecosystem and inspire other developers.
## How to Submit
1. **Prepare Your Documentation**: Write clear, concise documentation for your tool. Include:
- A brief description of what your tool does
- Installation instructions
- Usage examples
- Any necessary configuration steps
2. **Create a Pull Request**:
- Fork our [documentation repository](https://www.kaibanjs.com/discord)
- Add your tool documentation to the appropriate section
- Submit a pull request with your changes
3. **Review Process**: Our team will review your submission. We may ask for clarifications or suggest improvements.
## Guidelines
- Ensure your tool is well-tested and follows best practices
- Provide clear examples of how your tool can be used with KaibanJS
- Include any relevant license information
## Need Help?
If you have questions about submitting your tool or need assistance, join our [Discord community](https://www.kaibanjs.com/discord). Our friendly community members and developers are there to help!
:::tip
Before submitting, check if a similar tool already exists. If it does, consider contributing improvements to the existing tool instead.
:::
We're excited to see what you've created and how it can enhance the Javascript AI ecosystem!
### ./src/tools-docs/custom-tools/07-Request a Tool.md
//--------------------------------------------
// File: ./src/tools-docs/custom-tools/07-Request a Tool.md
//--------------------------------------------
---
title: Request a Tool
description: Learn how to request new tool integrations for KaibanJS and participate in community discussions about desired features.
---
# Request a Tool
Is there a tool you'd love to see integrated with KaibanJS? We want to hear about it! Your input helps us prioritize new integrations and ensure KaibanJS meets the community's needs.
## How to Request
1. **Check Existing Tools**: First, make sure the tool you're looking for doesn't already exist in our documentation or isn't currently under development.
2. **Submit a Request**:
- Open an issue in our [GitHub repository](https://github.com/kaiban-ai/KaibanJS)
- Use the title format: "Tool Request: [Tool Name]"
- In the description, explain:
- What the tool does
- Why it would be valuable for KaibanJS users
- Any relevant links or documentation for the tool
3. **Community Discussion**: Other users can comment on and upvote tool requests, helping us prioritize integrations.
## Participate in Discussions
Once you've submitted a request, or if you see a request you're interested in:
- Engage in the discussion thread
- Provide additional use cases or scenarios
- Upvote requests you find valuable
Your active participation helps us understand the importance and potential impact of each requested tool.
## Need Help?
If you have questions about requesting a new integration or need assistance, join our [Discord community](https://www.kaibanjs.com/discord). Our friendly community members and developers are there to help!
:::tip
Before requesting, check if a similar tool already exists or if a request has already been made. If it has, consider adding your voice to the existing discussion instead.
:::
We're excited to hear about the tools you want to use with KaibanJS and how they can enhance your projects!
### ./src/tools-docs/kaibanjs-tools/02-Firecrawl.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/02-Firecrawl.md
//--------------------------------------------
---
title: Firecrawl
description: Firecrawl is a web scraping and crawling service designed to turn websites into LLM-ready data.
---
# Firecrawl Tool
## Description
[Firecrawl](https://www.firecrawl.dev/) is a powerful web scraping and crawling service designed specifically for AI applications. It excels at converting web content into clean, well-formatted data that's optimized for Large Language Models (LLMs).
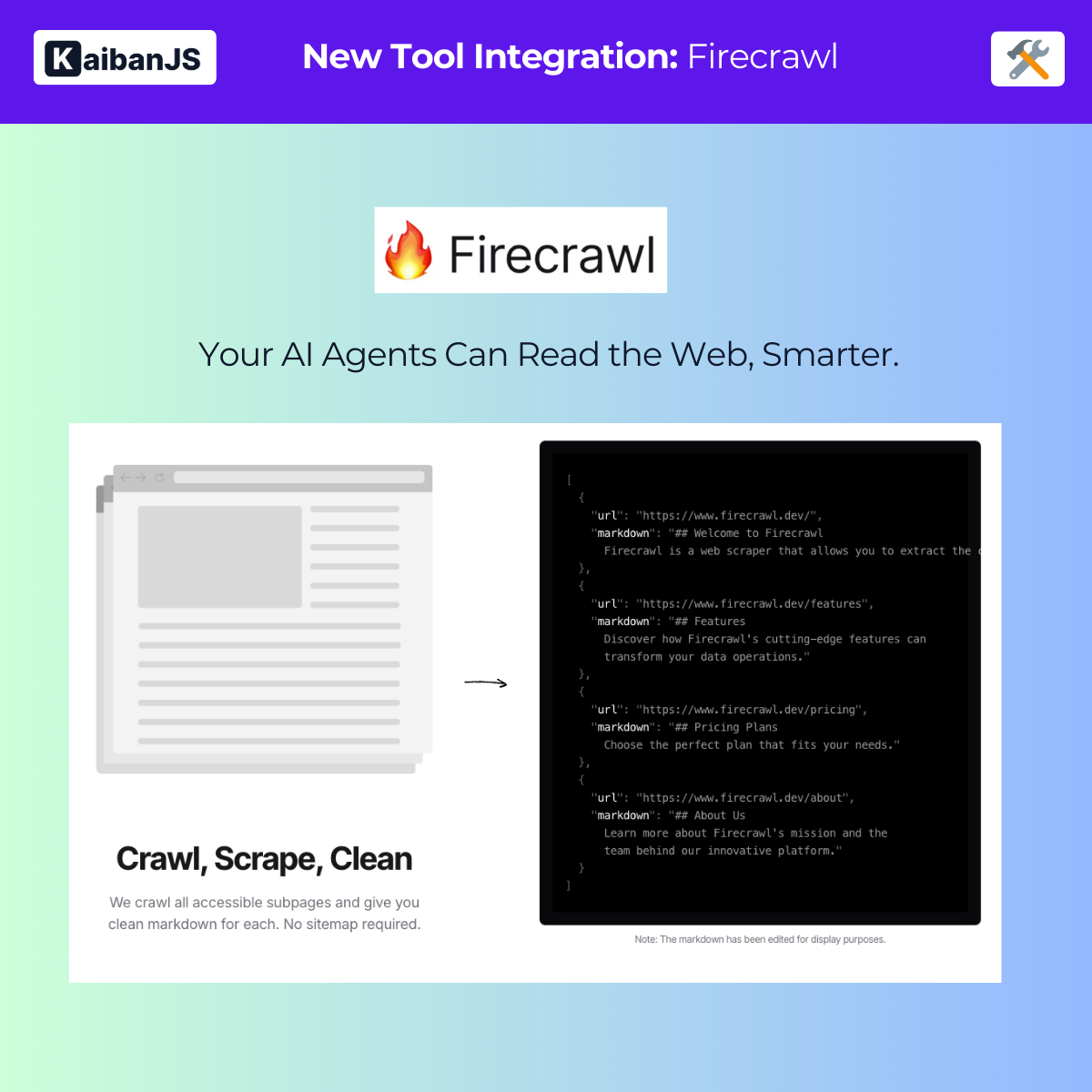
Enhance your agents with:
- **Dynamic Content Handling**: Scrape websites with dynamic content and JavaScript rendering
- **LLM-Ready Output**: Get clean, well-formatted markdown or structured data
- **Anti-Bot Protection**: Handles rate limits and anti-bot mechanisms automatically
- **Flexible Formats**: Choose between markdown and other structured data formats
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure that you have created an API Key at [Firecrawl](https://www.firecrawl.dev/) to enable web scraping functionality.
## Example
Utilize the Firecrawl tool as follows to enable your agent to extract content from websites:
```js
import { Firecrawl } from '@kaibanjs/tools';
const firecrawlTool = new Firecrawl({
apiKey: `FIRECRAWL_API_KEY`,
format: 'markdown'
});
const informationRetriever = new Agent({
name: 'Mary',
role: 'Information Retriever',
goal: 'Gather and present the most relevant and up-to-date information from various online sources.',
background: 'Search Specialist',
tools: [firecrawlTool]
});
```
## Parameters
- `apiKey` **Required**. The API key generated from [Firecrawl](https://www.firecrawl.dev/). Set `'ENV_FIRECRAWL_API_KEY'` as an environment variable or replace it directly with your API key.
- `format` **Optional**. The output format for the scraped content. Accepts either `'markdown'` (default) or `'html'`.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/tools-docs/kaibanjs-tools/03-Tavily.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/03-Tavily.md
//--------------------------------------------
---
title: Tavily Search
description: Tavily is an advanced search engine optimized for comprehensive, accurate, and trusted results.
---
# Tavily Search Results Tool
## Description
[Tavily](https://tavily.com/) is an advanced search engine specifically designed for AI applications. It excels at providing comprehensive and accurate search results, with a particular focus on current events and real-time information.
:::tip[Try it in the Kaiban Board!]
Want to see this tool in action? Check out our interactive Kaiban Board! [Try it now!](https://www.kaibanjs.com/share/mffyPAxJqLi9s5H27t9p)
:::
Enhance your agents with:
- **Trusted Results**: Get accurate and reliable search results
- **Real-Time Information**: Access current events and up-to-date data
- **LLM-Ready Output**: Receive well-structured JSON data ready for consumption
- **Smart Filtering**: Benefit from content relevance scoring and filtering
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure that you have created an API Key at [Tavily](https://tavily.com/) to enable search functionality.
## Example
Utilize the Tavily Search Results tool as follows to enable your agent to search for current information:
```js
import { TavilySearchResults } from '@kaibanjs/tools';
const tavilyTool = new TavilySearchResults({
apiKey: 'your-tavily-api-key',
maxResults: 5
});
const newsAnalyzer = new Agent({
name: 'Sarah',
role: 'News Analyst',
goal: 'Find and analyze current events and trending topics',
background: 'Research Specialist',
tools: [tavilyTool]
});
```
## Parameters
- `apiKey` **Required**. The API key generated from [Tavily](https://tavily.com/). Provide your API key directly as a string.
- `maxResults` **Optional**. The maximum number of search results to return. Defaults to `5`.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/04-Serper.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/04-Serper.md
//--------------------------------------------
---
title: Serper Search
description: Serper is a Google Search API that provides fast, reliable access to Google search results.
---
# Serper Search Tool
## Description
[Serper](https://serper.dev/) is a powerful Google Search API that provides quick and reliable access to Google search results. It's particularly useful for gathering current news, web content, and comprehensive search data.

:::tip[Try it in the Kaiban Board!]
Want to see this tool in action? Check out our interactive Kaiban Board! [Try it now!](https://www.kaibanjs.com/share/OEznrOejkRNuf12tHj5i)
:::
Enhance your agents with:
- **Google Search Results**: Access Google's search engine capabilities
- **News Search**: Dedicated news search functionality
- **Multiple Search Types**: Support for web, news, and image searches
- **Structured Data**: Well-formatted JSON responses ready for LLM processing
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure that you have created an API Key at [Serper](https://serper.dev/) to enable search functionality.
## Example
Here's how to use the Serper tool to create a news gathering and processing team:
```javascript
import { Serper } from '@kaibanjs/tools';
// Configure Serper tool
const serperTool = new Serper({
apiKey: 'your-serper-api-key',
type: 'news' // Can be 'news', 'search', or 'images'
});
// Create an agent with the serper tool
const newsGatherer = new Agent({
name: 'Echo',
role: 'News Gatherer',
goal: 'Collect recent news articles about specific events',
background: 'Journalism',
tools: [serperTool]
});
// Create a team
const team = new Team({
name: 'News Research Team',
agents: [newsGatherer],
tasks: [/* your tasks */],
inputs: {
query: 'Your search query'
}
});
```
## Parameters
- `apiKey` **Required**. The API key generated from [Serper](https://serper.dev/). Provide your API key directly as a string.
- `type` **Optional**. The type of search to perform. Options:
- `'news'`: Search news articles
- `'search'`: Regular web search
- `'images'`: Image search
Defaults to `'search'`.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/05-Exa.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/05-Exa.md
//--------------------------------------------
---
title: Exa Search
description: Exa is an AI-powered search API that provides comprehensive research capabilities with neural search and content summarization.
---
# Exa Search Tool
## Description
[Exa](https://exa.ai/) is an advanced search API that combines neural search with content processing capabilities. It's particularly effective for in-depth research, academic content, and comprehensive data gathering.

:::tip[Try it in the Kaiban Board!]
Want to see this tool in action? Check out our interactive Kaiban Board! [Try it now!](https://www.kaibanjs.com/share/euD49bj9dv1OLlJ5VEaL)
:::
Enhance your agents with:
- **Neural Search**: Advanced semantic understanding of search queries
- **Content Processing**: Get full text, summaries, and highlights
- **Auto-prompt Enhancement**: Automatic query improvement
- **Structured Results**: Well-organized content with metadata
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure that you have created an API Key at [Exa](https://exa.ai/) to enable search functionality.
## Example
Here's how to use the Exa tool to create a research and writing team:
```javascript
import { ExaSearch } from '@kaibanjs/tools';
// Configure Exa tool
const exaSearch = new ExaSearch({
apiKey: 'your-exa-api-key',
type: 'neural',
contents: {
text: true,
summary: true,
highlights: true
},
useAutoprompt: true,
limit: 10
});
// Create a research agent
const researcher = new Agent({
name: 'DataMiner',
role: 'Research Specialist',
goal: 'Gather comprehensive information from reliable sources',
background: 'Expert in data collection and research',
tools: [exaSearch]
});
// Create a team
const team = new Team({
name: 'Research Team',
agents: [researcher],
tasks: [/* your tasks */],
inputs: {
topic: 'Your research topic'
}
});
```
## Parameters
- `apiKey` **Required**. The API key generated from [Exa](https://exa.ai/). Provide your API key directly as a string.
- `type` **Optional**. The type of search to perform. Options:
- `'neural'`: Semantic search using AI
- `'keyword'`: Traditional keyword-based search
Defaults to `'neural'`.
- `contents` **Optional**. Configure what content to retrieve:
- `text`: Get full text content
- `summary`: Get AI-generated summaries
- `highlights`: Get relevant text highlights
- `useAutoprompt` **Optional**. Enable AI query enhancement
- `limit` **Optional**. Number of results to return. Default is 10.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/06-WolframAlpha.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/06-WolframAlpha.md
//--------------------------------------------
---
title: Wolfram Alpha
description: Wolfram Alpha is a computational knowledge engine that provides precise calculations and scientific data analysis.
---
# Wolfram Alpha Tool
## Description
[Wolfram Alpha](https://www.wolframalpha.com/) is a powerful computational knowledge engine that provides precise calculations, mathematical analysis, and scientific data processing capabilities.

:::tip[Try it in the Kaiban Board!]
Want to see this tool in action? Check out our interactive Kaiban Board! [Try it now!](https://www.kaibanjs.com/share/rthD4nzacEpGzvlkyejU)
:::
Enhance your agents with:
- **Mathematical Computations**: Solve complex mathematical problems
- **Scientific Analysis**: Process scientific queries and calculations
- **Data Visualization**: Access visual representations of data
- **Formula Processing**: Work with mathematical and scientific formulas
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure that you have created an App ID at [Wolfram Alpha Developer Portal](https://developer.wolframalpha.com/) to enable computational functionality.
## Example
Here's how to use the Wolfram Alpha tool to create a scientific computing team:
```javascript
import { WolframAlphaTool } from '@kaibanjs/tools';
// Configure Wolfram tool
const wolframTool = new WolframAlphaTool({
appId: 'your-wolfram-app-id'
});
// Create computation agent
const mathScientist = new Agent({
name: 'Euler',
role: 'Mathematical and Scientific Analyst',
goal: 'Solve complex mathematical and scientific problems',
background: 'Advanced Mathematics and Scientific Computing',
tools: [wolframTool]
});
// Create a team
const team = new Team({
name: 'Scientific Computing Team',
agents: [mathScientist],
tasks: [/* your tasks */],
inputs: {
query: 'Calculate the orbital period of Mars around the Sun'
}
});
```
## Parameters
- `appId` **Required**. The App ID generated from [Wolfram Alpha Developer Portal](https://developer.wolframalpha.com/). Provide your App ID directly as a string.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/07-GithubIssues.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/07-GithubIssues.md
//--------------------------------------------
---
title: GitHub Issues
description: GitHub Issues tool provides access to repository issues with automatic pagination and structured data retrieval.
---
# GitHub Issues Tool
## Description
The GitHub Issues tool integrates with GitHub's API to fetch issues from specified repositories. It provides a clean, structured way to retrieve and analyze repository issues.
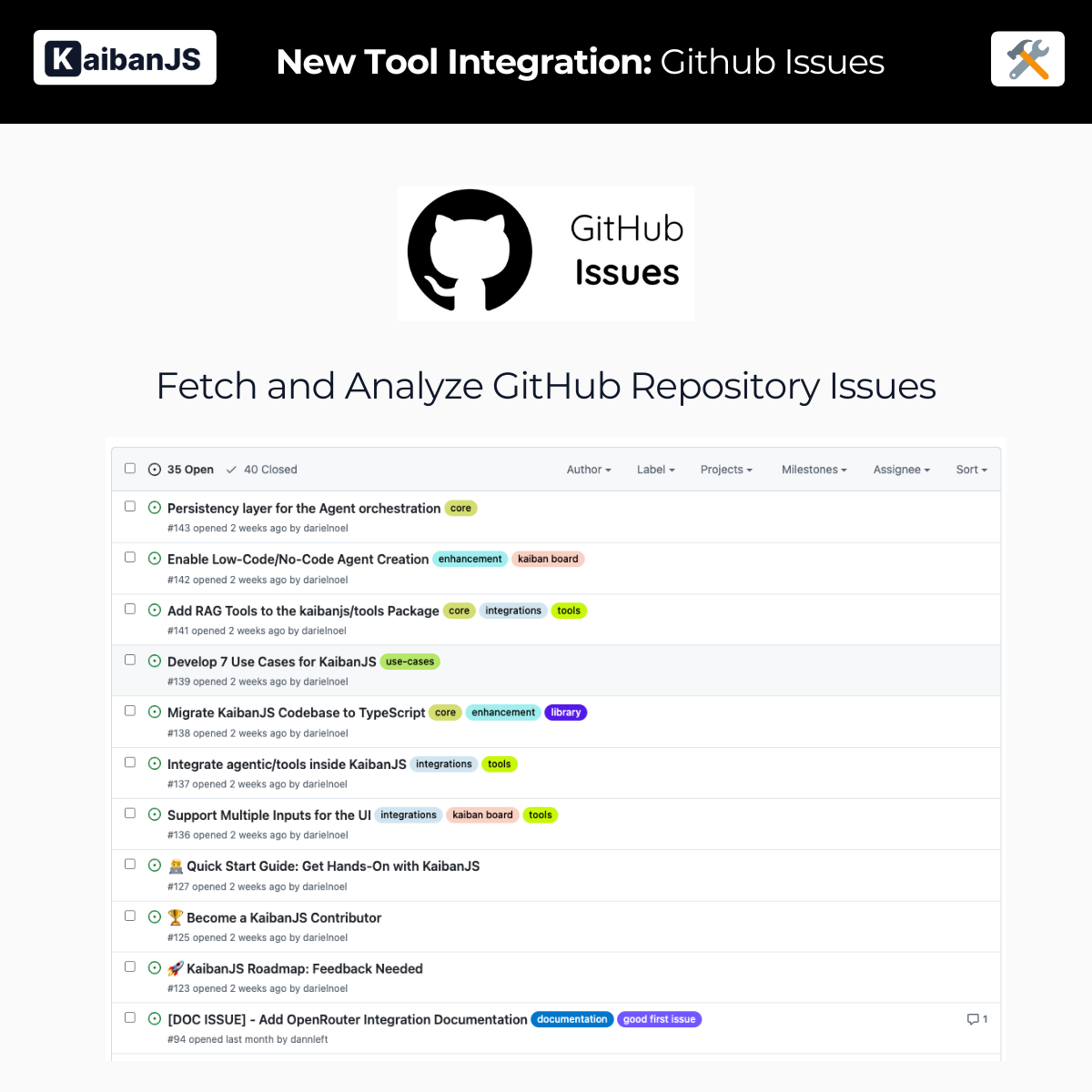
:::tip[Try it in the Kaiban Board!]
Want to see this tool in action? Check out our interactive Kaiban Board! [Try it now!](https://www.kaibanjs.com/share/VbAmEbFRKSDJuI5bESea)
:::
Enhance your agents with:
- **Issue Collection**: Fetch open issues from any public GitHub repository
- **Automatic Pagination**: Handle large sets of issues seamlessly
- **Structured Data**: Get well-formatted issue details and metadata
- **Flexible Authentication**: Work with or without GitHub tokens
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
A GitHub Personal Access Token is optional but recommended:
- Without token: 60 requests/hour limit
- With token: 5,000 requests/hour limit
Create your token at [GitHub Developer Settings](https://github.com/settings/tokens)
## Example
Here's how to use the GitHub Issues tool:
```javascript
import { GithubIssues } from '@kaibanjs/tools';
// Configure GitHub tool
const githubTool = new GithubIssues({
token: 'github_pat_...', // Optional: higher rate limits with token
limit: 20 // Optional: number of issues to fetch
});
// Create issue collector agent
const issueCollector = new Agent({
name: 'Luna',
role: 'Issue Collector',
goal: 'Gather and organize GitHub issues efficiently',
background: 'Specialized in data collection from GitHub repositories',
tools: [githubTool]
});
// Create a team
const team = new Team({
name: 'GitHub Issue Analysis Team',
agents: [issueCollector],
tasks: [/* your tasks */],
inputs: {
repository: 'https://github.com/owner/repo'
}
});
```
## Parameters
- `token` **Optional**. GitHub Personal Access Token for higher rate limits
- Without token: 60 requests/hour
- With token: 5,000 requests/hour
- `limit` **Optional**. Number of issues to fetch per request. Default is 10.
## Rate Limits
- **Authenticated**: 5,000 requests per hour
- **Unauthenticated**: 60 requests per hour
For more information about GitHub's API, visit: [GitHub REST API Documentation](https://docs.github.com/en/rest)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/08-SimpleRAG.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/08-SimpleRAG.md
//--------------------------------------------
---
title: Simple RAG Search
description: Simple RAG Search is a foundational RAG implementation tool designed for quick and efficient question-answering systems.
---
# Simple RAG Search Tool
## Description
Simple RAG Search is a powerful Retrieval-Augmented Generation (RAG) tool that provides a streamlined interface for building question-answering systems. It seamlessly integrates with langchain components to deliver accurate and context-aware responses.

Enhance your agents with:
- **Quick RAG Setup**: Get started with RAG in minutes using default configurations
- **Flexible Components**: Customize embeddings, vector stores, and language models
- **Efficient Processing**: Smart text chunking and processing for optimal results
- **OpenAI Integration**: Built-in support for state-of-the-art language models
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure you have an OpenAI API key to enable the RAG functionality.
## Example
Here's how to use the SimpleRAG tool to enable your agent to process and answer questions about text content:
```js
import { SimpleRAG } from '@kaibanjs/tools';
import { Agent, Task, Team } from 'kaibanjs';
// Create the tool instance
const simpleRAGTool = new SimpleRAG({
OPENAI_API_KEY: 'your-openai-api-key',
content: 'Your text content here'
});
// Create an agent with the tool
const knowledgeAssistant = new Agent({
name: 'Alex',
role: 'Knowledge Assistant',
goal: 'Process text content and answer questions accurately using RAG technology',
background: 'RAG Specialist',
tools: [simpleRAGTool]
});
// Create a task for the agent
const answerQuestionsTask = new Task({
description: 'Answer questions about the provided content using RAG technology',
expectedOutput: 'Accurate and context-aware answers based on the content',
agent: knowledgeAssistant
});
// Create a team
const ragTeam = new Team({
name: 'RAG Analysis Team',
agents: [knowledgeAssistant],
tasks: [answerQuestionsTask],
inputs: {
content: 'Your text content here',
query: 'What questions would you like to ask about the content?'
},
env: {
OPENAI_API_KEY: 'your-openai-api-key'
}
});
```
## Advanced Example with Pinecone
For more advanced use cases, you can configure SimpleRAG with a custom vector store:
```js
import { PineconeStore } from '@langchain/pinecone';
import { Pinecone } from '@pinecone-database/pinecone';
import { OpenAIEmbeddings } from '@langchain/openai';
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
model: 'text-embedding-3-small'
});
const pinecone = new Pinecone({
apiKey: process.env.PINECONE_API_KEY
});
const pineconeIndex = pinecone.Index('your-index-name');
const vectorStore = await PineconeStore.fromExistingIndex(embeddings, {
pineconeIndex
});
const simpleRAGTool = new SimpleRAG({
OPENAI_API_KEY: 'your-openai-api-key',
content: 'Your text content here',
embeddings: embeddings,
vectorStore: vectorStore
});
```
## Parameters
- `OPENAI_API_KEY` **Required**. Your OpenAI API key for embeddings and completions.
- `content` **Required**. The text content to process and answer questions about.
- `embeddings` **Optional**. Custom embeddings instance (defaults to OpenAIEmbeddings).
- `vectorStore` **Optional**. Custom vector store instance (defaults to MemoryVectorStore).
- `chunkOptions` **Optional**. Configuration for text chunking (size and overlap).
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/09-WebsiteSearch.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/09-WebsiteSearch.md
//--------------------------------------------
---
title: Website RAG Search
description: Website RAG Search is a specialized RAG tool for conducting semantic searches within website content.
---
# Website RAG Search Tool
## Description
Website RAG Search is a powerful tool that enables semantic search capabilities within website content. It combines HTML parsing with RAG technology to provide intelligent answers based on web content.
Enhance your agents with:
- **Smart Web Parsing**: Efficiently extracts and processes web content
- **Semantic Search**: Find relevant information beyond keyword matching
- **HTML Support**: Built-in HTML parsing with cheerio
- **Flexible Configuration**: Customize embeddings and vector stores for your needs
## Installation
First, install the KaibanJS tools package and cheerio:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure you have an OpenAI API key to enable the semantic search functionality.
## Example
Here's how to use the WebsiteSearch tool to enable your agent to search and analyze web content:
```js
import { WebsiteSearch } from '@kaibanjs/tools';
import { Agent, Task, Team } from 'kaibanjs';
// Create the tool instance
const websiteSearchTool = new WebsiteSearch({
OPENAI_API_KEY: 'your-openai-api-key',
url: 'https://example.com'
});
// Create an agent with the tool
const webAnalyst = new Agent({
name: 'Emma',
role: 'Web Content Analyst',
goal: 'Extract and analyze information from websites using semantic search',
background: 'Web Content Specialist',
tools: [websiteSearchTool]
});
// Create a task for the agent
const websiteAnalysisTask = new Task({
description: 'Search and analyze the content of {url} to answer: {query}',
expectedOutput: 'Detailed answers based on the website content',
agent: webAnalyst
});
// Create a team
const webSearchTeam = new Team({
name: 'Web Analysis Team',
agents: [webAnalyst],
tasks: [websiteAnalysisTask],
inputs: {
url: 'https://example.com',
query: 'What would you like to know about this website?'
},
env: {
OPENAI_API_KEY: 'your-openai-api-key'
}
});
```
## Advanced Example with Pinecone
For more advanced use cases, you can configure WebsiteSearch with a custom vector store:
```js
import { PineconeStore } from '@langchain/pinecone';
import { Pinecone } from '@pinecone-database/pinecone';
import { OpenAIEmbeddings } from '@langchain/openai';
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
model: 'text-embedding-3-small'
});
const pinecone = new Pinecone({
apiKey: process.env.PINECONE_API_KEY
});
const pineconeIndex = pinecone.Index('your-index-name');
const vectorStore = await PineconeStore.fromExistingIndex(embeddings, {
pineconeIndex
});
const websiteSearchTool = new WebsiteSearch({
OPENAI_API_KEY: 'your-openai-api-key',
url: 'https://example.com',
embeddings: embeddings,
vectorStore: vectorStore
});
```
## Parameters
- `OPENAI_API_KEY` **Required**. Your OpenAI API key for embeddings and completions.
- `url` **Required**. The website URL to search within.
- `embeddings` **Optional**. Custom embeddings instance (defaults to OpenAIEmbeddings).
- `vectorStore` **Optional**. Custom vector store instance (defaults to MemoryVectorStore).
- `chunkOptions` **Optional**. Configuration for text chunking (size and overlap).
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/10-PDFSearch.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/10-PDFSearch.md
//--------------------------------------------
---
title: PDF RAG Search
description: PDF RAG Search is a specialized RAG tool for conducting semantic searches within PDF documents.
---
# PDF RAG Search Tool
## Description
PDF RAG Search is a versatile tool that enables semantic search capabilities within PDF documents. It supports both Node.js and browser environments, making it perfect for various PDF analysis scenarios.
Enhance your agents with:
- **PDF Processing**: Efficient extraction and analysis of PDF content
- **Cross-Platform**: Works in both Node.js and browser environments
- **Smart Chunking**: Intelligent document segmentation for optimal results
- **Semantic Search**: Find relevant information beyond keyword matching
## Installation
First, install the KaibanJS tools package and the required PDF processing library:
For Node.js:
```bash
npm install @kaibanjs/tools pdf-parse
```
For Browser:
```bash
npm install @kaibanjs/tools pdfjs-dist
```
## API Key
Before using the tool, ensure you have an OpenAI API key to enable the semantic search functionality.
## Example
Here's how to use the PDFSearch tool to enable your agent to search and analyze PDF content:
```js
import { PDFSearch } from '@kaibanjs/tools';
import { Agent, Task, Team } from 'kaibanjs';
// Create the tool instance
const pdfSearchTool = new PDFSearch({
OPENAI_API_KEY: 'your-openai-api-key',
file: 'https://example.com/documents/sample.pdf'
});
// Create an agent with the tool
const documentAnalyst = new Agent({
name: 'David',
role: 'Document Analyst',
goal: 'Extract and analyze information from PDF documents using semantic search',
background: 'PDF Content Specialist',
tools: [pdfSearchTool]
});
// Create a task for the agent
const pdfAnalysisTask = new Task({
description: 'Analyze the PDF document at {file} and answer: {query}',
expectedOutput: 'Detailed answers based on the PDF content',
agent: documentAnalyst
});
// Create a team
const pdfAnalysisTeam = new Team({
name: 'PDF Analysis Team',
agents: [documentAnalyst],
tasks: [pdfAnalysisTask],
inputs: {
file: 'https://example.com/documents/sample.pdf',
query: 'What would you like to know about this PDF?'
},
env: {
OPENAI_API_KEY: 'your-openai-api-key'
}
});
```
## Advanced Example with Pinecone
For more advanced use cases, you can configure PDFSearch with a custom vector store:
```js
import { PineconeStore } from '@langchain/pinecone';
import { Pinecone } from '@pinecone-database/pinecone';
import { OpenAIEmbeddings } from '@langchain/openai';
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
model: 'text-embedding-3-small'
});
const pinecone = new Pinecone({
apiKey: process.env.PINECONE_API_KEY
});
const pineconeIndex = pinecone.Index('your-index-name');
const vectorStore = await PineconeStore.fromExistingIndex(embeddings, {
pineconeIndex
});
const pdfSearchTool = new PDFSearch({
OPENAI_API_KEY: 'your-openai-api-key',
file: 'https://example.com/documents/sample.pdf',
embeddings: embeddings,
vectorStore: vectorStore
});
```
## Parameters
- `OPENAI_API_KEY` **Required**. Your OpenAI API key for embeddings and completions.
- `file` **Required**. URL or local path to the PDF file to analyze.
- `embeddings` **Optional**. Custom embeddings instance (defaults to OpenAIEmbeddings).
- `vectorStore` **Optional**. Custom vector store instance (defaults to MemoryVectorStore).
- `chunkOptions` **Optional**. Configuration for text chunking (size and overlap).
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/11-TextFileSearch.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/11-TextFileSearch.md
//--------------------------------------------
---
title: TextFile RAG Search
description: TextFile RAG Search is a specialized RAG tool for conducting semantic searches within plain text files.
---
# TextFile RAG Search Tool
## Description
TextFile RAG Search is a specialized tool that enables semantic search capabilities within plain text files. It's designed to process and analyze text documents efficiently using RAG technology.

Enhance your agents with:
- **Text Processing**: Efficient analysis of plain text documents
- **Smart Chunking**: Intelligent text segmentation for optimal results
- **Semantic Search**: Find relevant information beyond keyword matching
- **Flexible Integration**: Easy integration with existing text workflows
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure you have an OpenAI API key to enable the semantic search functionality.
## Example
Here's how to use the TextFileSearch tool to enable your agent to search and analyze text content:
```js
import { TextFileSearch } from '@kaibanjs/tools';
import { Agent, Task, Team } from 'kaibanjs';
// Create the tool instance
const textSearchTool = new TextFileSearch({
OPENAI_API_KEY: 'your-openai-api-key',
file: 'https://example.com/documents/sample.txt'
});
// Create an agent with the tool
const textAnalyst = new Agent({
name: 'Sarah',
role: 'Text Analyst',
goal: 'Extract and analyze information from text documents using semantic search',
background: 'Text Content Specialist',
tools: [textSearchTool]
});
// Create a task for the agent
const textAnalysisTask = new Task({
description: 'Analyze the text file at {file} and answer: {query}',
expectedOutput: 'Detailed answers based on the text content',
agent: textAnalyst
});
// Create a team
const textAnalysisTeam = new Team({
name: 'Text Analysis Team',
agents: [textAnalyst],
tasks: [textAnalysisTask],
inputs: {
file: 'https://example.com/documents/sample.txt',
query: 'What would you like to know about this text file?'
},
env: {
OPENAI_API_KEY: 'your-openai-api-key'
}
});
```
## Advanced Example with Pinecone
For more advanced use cases, you can configure TextFileSearch with a custom vector store:
```js
import { PineconeStore } from '@langchain/pinecone';
import { Pinecone } from '@pinecone-database/pinecone';
import { OpenAIEmbeddings } from '@langchain/openai';
const embeddings = new OpenAIEmbeddings({
apiKey: process.env.OPENAI_API_KEY,
model: 'text-embedding-3-small'
});
const pinecone = new Pinecone({
apiKey: process.env.PINECONE_API_KEY
});
const pineconeIndex = pinecone.Index('your-index-name');
const vectorStore = await PineconeStore.fromExistingIndex(embeddings, {
pineconeIndex
});
const textSearchTool = new TextFileSearch({
OPENAI_API_KEY: 'your-openai-api-key',
file: 'https://example.com/documents/sample.txt',
embeddings: embeddings,
vectorStore: vectorStore
});
```
## Parameters
- `OPENAI_API_KEY` **Required**. Your OpenAI API key for embeddings and completions.
- `file` **Required**. URL or local path to the text file to analyze.
- `embeddings` **Optional**. Custom embeddings instance (defaults to OpenAIEmbeddings).
- `vectorStore` **Optional**. Custom vector store instance (defaults to MemoryVectorStore).
- `chunkOptions` **Optional**. Configuration for text chunking (size and overlap).
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/12-ZapierWebhook.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/12-ZapierWebhook.md
//--------------------------------------------
---
title: Zapier Webhook
description: Zapier Webhook is a tool that enables seamless integration with Zapier's automation platform, allowing you to trigger workflows and connect with thousands of apps.
---
# Zapier Webhook Tool
## Description
[Zapier](https://zapier.com/) is a powerful automation platform that connects thousands of apps and services. The Zapier Webhook tool enables AI agents to trigger workflows and automate tasks across various applications using Zapier's webhook functionality.
Enhance your agents with:
- **Multi-App Integration**: Connect with thousands of apps and services
- **Flexible Automation**: Trigger complex workflows with a single webhook
- **Structured Data**: Send formatted data using Zod schema validation
- **Secure Communication**: Built-in security features and environment variable support
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## Webhook URL
Before using the tool, ensure that you have created a webhook trigger in Zapier and obtained the webhook URL. This URL will be used to send data to your Zap.
## Example
Here's how to use the Zapier Webhook tool to send notifications and trigger automations:
```javascript
import { ZapierWebhook } from '@kaibanjs/tools';
import { z } from 'zod';
const webhookTool = new ZapierWebhook({
url: 'YOUR_ZAPIER_WEBHOOK_URL',
schema: z.object({
message: z.string().describe('Message content'),
channel: z.string().describe('Target channel'),
priority: z.enum(['high', 'medium', 'low']).describe('Message priority')
})
});
const notificationAgent = new Agent({
name: 'NotifyBot',
role: 'Notification Manager',
goal: 'Send timely and relevant notifications through various channels',
background: 'Communication Specialist',
tools: [webhookTool]
});
```
## Parameters
- `url` **Required**. The webhook URL from your Zapier trigger. Store this in an environment variable for security.
- `schema` **Required**. A Zod schema that defines the structure of the data you'll send to Zapier.
## Common Use Cases
1. **Notifications**
- Send email alerts
- Post to chat platforms
- Push mobile notifications
2. **Data Integration**
- Update spreadsheets
- Create tasks
- Log events
3. **Workflow Automation**
- Trigger multi-step Zaps
- Start automated processes
- Connect multiple services
## Best Practices
1. **Security**
- Store webhook URLs in environment variables
- Use HTTPS endpoints only
- Never expose URLs in client-side code
2. **Data Validation**
- Define clear schemas
- Validate input types
- Handle edge cases
3. **Error Handling**
- Implement proper error handling
- Monitor webhook responses
- Handle rate limits
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/13-MakeWebhook.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/13-MakeWebhook.md
//--------------------------------------------
---
title: Make Webhook
description: Make Webhook is a tool that enables seamless integration with Make's automation platform (formerly Integromat), allowing you to trigger scenarios and connect with thousands of apps.
---
# Make Webhook Tool
## Description
[Make](https://www.make.com/) (formerly Integromat) is a powerful automation platform that connects thousands of apps and services. The Make Webhook tool enables AI agents to trigger scenarios and automate tasks across various applications using Make's webhook functionality.

Enhance your agents with:
- **Multi-App Integration**: Connect with thousands of apps and services
- **Scenario Automation**: Trigger complex scenarios with a single webhook
- **Structured Data**: Send formatted data using Zod schema validation
- **Secure Communication**: Built-in security features and environment variable support
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## Webhook URL
Before using the tool, ensure that you have created a webhook trigger in Make and obtained the webhook URL. This URL will be used to send data to your scenario.
## Example
Here's how to use the Make Webhook tool to send data and trigger automations:
```javascript
import { MakeWebhook } from '@kaibanjs/tools';
import { z } from 'zod';
const webhookTool = new MakeWebhook({
url: 'YOUR_MAKE_WEBHOOK_URL',
schema: z.object({
event: z.string().describe('Event type'),
data: z.object({
id: z.string(),
timestamp: z.string(),
details: z.record(z.any())
}).describe('Event data'),
source: z.string().describe('Event source')
})
});
const automationAgent = new Agent({
name: 'AutoBot',
role: 'Automation Manager',
goal: 'Trigger and manage automated workflows across various systems',
background: 'System Integration Specialist',
tools: [webhookTool]
});
```
## Parameters
- `url` **Required**. The webhook URL from your Make trigger. Store this in an environment variable for security.
- `schema` **Required**. A Zod schema that defines the structure of the data you'll send to Make.
## Common Use Cases
1. **Data Processing**
- Transform data formats
- Filter and route information
- Aggregate multiple sources
2. **System Integration**
- Connect applications
- Sync data between systems
- Automate workflows
3. **Event Processing**
- Handle real-time events
- Process webhooks
- Trigger automated responses
## Best Practices
1. **Security**
- Store webhook URLs in environment variables
- Use HTTPS endpoints only
- Never expose URLs in client-side code
2. **Data Validation**
- Define clear schemas
- Validate input types
- Handle edge cases
3. **Error Handling**
- Implement proper error handling
- Monitor webhook responses
- Handle rate limits
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/14-JinaUrlToMarkdown.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/14-JinaUrlToMarkdown.md
//--------------------------------------------
---
title: Jina URL to Markdown
description: Web URLs to LLM-Ready Markdown - A powerful tool that converts web content into clean, LLM-ready markdown format using Jina.ai's advanced web scraping capabilities.
---
# Jina URL to Markdown Tool
## Description
[Jina](https://jina.ai/) is a powerful web scraping and crawling service designed to turn websites into LLM-ready data. The Jina URL to Markdown tool enables AI agents to extract clean, well-formatted content from websites, making it ideal for AI applications and large language models.
## Acknowledgments
Special thanks to [Aitor Roma](https://github.com/aitorroma) and the [Nimbox360](https://nimbox360.com/) team for their valuable contribution to this tool integration.
Enhance your agents with:
- **Advanced Web Scraping**: Handle complex websites with dynamic content
- **Clean Markdown Output**: Get perfectly formatted, LLM-ready content
- **Anti-bot Protection**: Built-in handling of common scraping challenges
- **Configurable Options**: Multiple output formats and customization options
- **Content Optimization**: Automatic cleaning and formatting for AI processing
## Installation
First, install the KaibanJS tools package:
```bash
npm install @kaibanjs/tools
```
## API Key
Before using the tool, ensure that you have obtained an API key from [Jina](https://jina.ai/). This key will be used to authenticate your requests to the Jina API.
## Example
Here's how to use the Jina URL to Markdown tool to extract and process web content:
```javascript
import { JinaUrlToMarkdown } from '@kaibanjs/tools';
import { z } from 'zod';
const jinaTool = new JinaUrlToMarkdown({
apiKey: 'YOUR_JINA_API_KEY',
options: {
retainImages: 'none',
// Add any other Jina-specific options here
}
});
const contentAgent = new Agent({
name: 'WebProcessor',
role: 'Content Extractor',
goal: 'Extract and process web content into clean, LLM-ready format',
background: 'Specialized in web content processing and formatting',
tools: [jinaTool]
});
```
## Parameters
- `apiKey` **Required**. Your Jina API key. Store this in an environment variable for security.
- `options` **Optional**. Configuration options for the Jina API:
- `retainImages`: Control image handling ('all', 'none', or 'selected')
- `targetSelector`: Specify HTML elements to focus on
- Additional options as supported by Jina's API
## Common Use Cases
1. **Content Extraction**
- Clean blog posts for analysis
- Extract documentation
- Process news articles
- Gather research papers
2. **Data Processing**
- Convert web content to training data
- Build knowledge bases
- Create documentation archives
- Process multiple pages in bulk
3. **Content Analysis**
- Extract key information
- Analyze web content structure
- Prepare content for LLM processing
- Generate summaries
## Best Practices
1. **URL Selection**
- Verify URL accessibility
- Check robots.txt compliance
- Consider rate limits
- Handle dynamic content appropriately
2. **Content Processing**
- Use appropriate selectors
- Configure image handling
- Handle multilingual content
- Validate output format
3. **Error Handling**
- Implement retry logic
- Handle timeouts gracefully
- Monitor API limits
- Log processing errors
## Contact Jina
Need help with the underlying web scraping technology? You can reach out to the Jina team:
- Twitter: [@JinaAI_](https://twitter.com/JinaAI_)
- Website: [jina.ai](https://jina.ai/)
- Documentation: [Jina Docs](https://docs.jina.ai/)
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/kaibanjs-tools/20-Contributing.md
//--------------------------------------------
// File: ./src/tools-docs/kaibanjs-tools/20-Contributing.md
//--------------------------------------------
---
title: Contributing Tools
description: Join us in expanding KaibanJS's tool ecosystem by contributing new integrations and capabilities.
---
# Contributing Tools
We're actively expanding our tool ecosystem and welcome contributions from the community! Here's how you can get involved:
## How to Contribute
1. **Pick a Tool**: Choose a tool or service you'd like to integrate
2. **Create Integration**: Follow our [Tools Development README](https://github.com/kaiban-ai/KaibanJS/blob/main/packages/tools/README.md) to set up your local environment.
3. **Test & Document**: Ensure proper testing and documentation
4. **Submit PR**: Create a pull request with your contribution
### Development Resources
- Check our [Tool Implementations](https://github.com/kaiban-ai/KaibanJS/tree/main/packages/tools/src) for examples and patterns
- Join our [Discord](https://kaibanjs.com/discord) for development support
## Share Your Ideas
Not ready to contribute code? You can still help:
- Suggest new tools we should add
- Share your use cases and needs
- Report compatibility issues
- Provide feedback on existing tools
Create a [GitHub issue](https://github.com/kaiban-ai/KaibanJS/issues) or join our Discord to discuss tool development.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We're all ears!
:::
### ./src/tools-docs/langchain-tools/02-SearchApi.md
//--------------------------------------------
// File: ./src/tools-docs/langchain-tools/02-SearchApi.md
//--------------------------------------------
---
title: SearchApi Tool
description: SearchApi is a versatile search engine API that allows developers to integrate search capabilities into their applications.
---
# SearchApi Tool
## Description
[SearchApi](https://www.searchapi.io/) is a versatile search engine API that allows developers to integrate search capabilities into their applications. It supports various search engines, making it a flexible tool for retrieving relevant information from different sources.
Enhance your agents with:
- **Multi-Engine Search**: Use different search engines like Google News, Bing, and more, depending on your needs.
- **Customizable Queries**: Easily configure your search queries with various parameters to tailor the results.
:::tip[Try it Out in the Playground!]
Before diving into the installation and coding, why not experiment directly with our interactive playground? [Try it now!](https://www.kaibanjs.com/share/A9fdCxrlUK81qDeFRdzF)
:::
## Installation
Before using the tool, ensure that you have created an API Key at [SearchApi](https://www.searchapi.io/) to enable search functionality.
## Example
Utilize the SearchApi tool as follows to enable your agent to perform searches with customizable engines:
```js
import { SearchApi } from '@langchain/community/tools/searchapi';
const searchTool = new SearchApi('ENV_SEARCH_API_KEY', {
engine: "google_news",
});
const informationRetriever = new Agent({
name: 'Mary',
role: 'Information Retriever',
goal: 'Gather and present the most relevant and up-to-date information from various online sources.',
background: 'Search Specialist',
tools: [searchTool]
});
```
## Parameters
- `apiKey` **Required**. The API key generated from [SearchApi](https://www.searchapi.io/). Set `'ENV_SEARCH_API_KEY'` as an environment variable or replace it directly with your API key.
- `engine` **Optional**. The search engine you want to use. Some options include `"google_news"`, `"bing"`, and others, depending on what is supported by SearchApi.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/tools-docs/langchain-tools/03-DallE.md
//--------------------------------------------
// File: ./src/tools-docs/langchain-tools/03-DallE.md
//--------------------------------------------
---
title: Dall-E Tool
description: Dall-E by OpenAI is an advanced AI model that generates images from textual descriptions.
---
# Dall-E Tool
## Description
[DALL-E](https://openai.com/index/dall-e-3/) by OpenAI is an advanced AI model that generates images from textual descriptions. This tool allows you to integrate DALL-E's capabilities into your applications, enabling the creation of unique and creative visual content based on specified prompts.
Enhance your agents with:
- **AI-Generated Imagery**: Create custom images based on textual input using state-of-the-art AI technology.
- **Creative Flexibility**: Use specific prompts to guide the generation of visuals, tailored to your needs.
:::tip[Try it Out in the Playground!]
Before diving into the installation and coding, why not experiment directly with our interactive playground? [Try it now!](https://www.kaibanjs.com/share/UNAC47GR4NUQfZoU5V0w)
:::
## Installation
Before using the tool, ensure you have created an API Key at [OpenAI](https://openai.com/) to enable image generation functionality.
## Example
Utilize the DallEAPIWrapper tool as follows to enable your agent to generate images based on specific prompts:
```js
import { DallEAPIWrapper } from "@langchain/openai";
const dallE = new DallEAPIWrapper({
n: 1, // If it is not 1 it gives an error
model: "dall-e-3", // Default
apiKey: 'ENV_OPENAI_API_KEY',
});
const creativeDesigner = new Agent({
name: 'Mary',
role: 'Creative Designer',
goal: 'Generate unique and creative visual content based on specific prompts and concepts.',
background: 'Digital Artist',
tools: [dallE]
});
```
## Parameters
- `n` **Required**. Number of images to generate. Must be set to `1` to avoid errors.
- `model` **Required**. The model version to use. Default is `"dall-e-3"`.
- `apiKey` **Required**. The API key generated from [OpenAI](https://openai.com/). Set `'ENV_OPENAI_API_KEY'` as an environment variable or replace it directly with your API key.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/tools-docs/langchain-tools/04-TavilySearchResults.md
//--------------------------------------------
// File: ./src/tools-docs/langchain-tools/04-TavilySearchResults.md
//--------------------------------------------
---
title: TavilySearchResults Tool
description: Tavily Search is a platform that offers advanced search capabilities, designed to efficiently retrieve up-to-date information.
---
# TavilySearchResults Tool
## Description
[Tavily](https://app.tavily.com/) is a platform that offers advanced search capabilities, designed to efficiently retrieve up-to-date information.
Enhance your agents with:
- **Custom Search**: Quickly and accurately retrieve relevant search results.
- **Simple Integration**: Easily configure your search tool with adjustable parameters.
:::tip[Try it Out in the Playground!]
Before diving into the installation and coding, why not experiment directly with our interactive playground? [Try it now!](https://www.kaibanjs.com/share/9lyzu1VjBFPOl6FRgNWu)
:::
## Installation
Before using the tool, make sure to create an API Key at [Tavily](https://app.tavily.com/) to enable search functionality.
## Example
Utilize the TavilySearchResults tool as follows to enable your agent to search for up-to-date information:
```js
import { TavilySearchResults } from '@langchain/community/tools/tavily_search';
const searchTool = new TavilySearchResults({
maxResults: 1,
apiKey: 'ENV_TRAVILY_API_KEY',
});
const newsAggregator = new Agent({
name: 'Mary',
role: 'News Aggregator',
goal: 'Aggregate and deliver the most relevant news and updates based on specific queries.',
background: 'Media Analyst',
tools: [searchTool]
});
```
## Parameters
- `maxResults` **Required**. The maximum number of results you want to retrieve.
- `apiKey` **Required**. The API key generated from [Tavily](https://app.tavily.com/). Set `'ENV_TRAVILY_API_KEY'` as an environment variable or replace it directly with your API key.
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/tools-docs/langchain-tools/05-More Tools.md
//--------------------------------------------
// File: ./src/tools-docs/langchain-tools/05-More Tools.md
//--------------------------------------------
---
title: More Tools
description: An overview of additional LangChain tools that can potentially enhance your AI agents' capabilities in KaibanJS.
---
# More Tools
While we've covered some specific LangChain tools in detail, there are many more available that can potentially be integrated with KaibanJS. This page provides an overview of additional tools you might find useful.
## Additional LangChain Tools
LangChain offers a wide variety of tools. You can find the full list and detailed documentation for all available tools in the [LangChain Tools documentation](https://js.langchain.com/v0.2/docs/integrations/tools/).
Some notable tools include:
1. **Search Tools**
- DuckDuckGoSearch: Perform web searches using the DuckDuckGo engine.
- Tavily Search: An AI-powered search engine for more contextual results.
2. **AI Services**
- Dall-E: Generate images from text descriptions.
- ChatGPT Plugins: Integrate various ChatGPT plugins for extended functionality.
3. **Productivity Tools**
- Gmail: Interact with Gmail for email-related tasks.
- Google Calendar: Manage calendar events and schedules.
- Google Places: Access information about locations and businesses.
4. **Development Tools**
- Python REPL: Execute Python code within your agent.
- AWS Lambda: Integrate with AWS Lambda functions.
5. **Knowledge Bases**
- Wikipedia: Access and search Wikipedia content.
- WolframAlpha: Perform computational and factual queries.
6. **Social Media**
- Discord Tool: Interact with Discord servers and channels.
7. **Web Interaction**
- Web Browser Tool: Allow your agent to browse and interact with websites.
## Integration Considerations
While these tools are available in LangChain, their direct compatibility with KaibanJS may vary. We recommend:
1. Checking the [LangChain documentation](https://js.langchain.com/v0.2/docs/integrations/tools/) for the most up-to-date information on each tool.
2. Testing the tool in a controlled environment before integrating it into your KaibanJS project.
3. Referring to our Custom Tools guide if you need to adapt a LangChain tool for use with KaibanJS.
## Community Contributions
Have you successfully integrated a LangChain tool with KaibanJS that's not listed in our main documentation? We encourage you to share your experience and contribute to our growing knowledge base!
:::tip[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/use-cases/01-Sports News Reporting.md
//--------------------------------------------
// File: ./src/use-cases/01-Sports News Reporting.md
//--------------------------------------------
---
title: Sports News Reporting
description: Discover how to automate sports news reporting with KaibanJS and LangChain tools. Learn to set up intelligent agents that gather real-time sports data and generate detailed articles, enhancing the efficiency and quality of your news coverage.
---
In the fast-paced world of sports journalism, covering grand-scale events like the Copa America final demands not only rapid response but also an insightful analysis. Traditional methods often fall short, ensnared by slow, manual processes that can't keep pace with live sports.
VIDEO
:::tip[Try it Out in the Playground!]
Curious about how this solution comes together? Explore it interactively in our playground before getting into the details. [Try it now!](https://www.kaibanjs.com/share/9lyzu1VjBFPOl6FRgNWu)
:::
### Traditional Approach Challenges
:::challenges
When reporting on significant sports events like the Copa America final, journalists traditionally follow a detailed, manual process. Below is an outline of the typical steps involved, highlighted for emphasis:
1. **Gathering Data:** Journalists comb through various sports websites to find the final score, player statistics, and key plays, all under the pressing deadlines.
2. **Interviews and Quotes:** Reporters quickly gather reactions from players and coaches, trying to capture the emotional aftermath of the match before their competitors.
3. **Writing and Structuring:** Back in the newsroom, writers piece together their findings, striving to create a narrative that captures the essence of the game.
4. **Editing and Publishing:** Editors polish the articles for clarity and engagement, racing against time to publish while the news is still fresh.
*Note: In this use case, the publishing step is not currently automated by KaibanJS to maintain simplicity in the workflow.*
:::
### The Agentic Solution
Now, imagine this scenario optimized with KaibanJS automation:
- **Event:** Copa America Final, 2024
- **Query:** "Who won the Copa America in 2024?"
Before diving into the process, let's understand the roles of the **key Agents** involved:
:::agents
**Scout Agent:** This agent is responsible for automated data collection. As soon as the game concludes, the Scout Agent springs into action, using advanced algorithms to retrieve detailed game data such as scores, player performances, and key moments—all in real time and without human intervention.
**Writer Agent:** After data collection, the Writer Agent takes over. This agent processes the collected data to generate engaging and accurate content. It crafts articles that not only report the facts but also weave in narrative elements such as player quotes and strategic analyses, creating stories that capture the drama and excitement of the game.
:::
#### Process Overview
Now that you are familiar with the agents and their roles, let's explore the process they follow to transform live game data into engaging content.
:::tasks
1. **Automated Data Collection:** As the final whistle blows, a Scout Agent immediately retrieves detailed game data. It captures Argentina’s dramatic 2-1 victory over Colombia, pinpointing key plays and standout player performances without human delay.
2. **Content Creation:** A Writer Agent rapidly processes this information, crafting an enthralling article titled "Argentina Edges Out Colombia: A Copa America Final to Remember." The piece spotlights Argentina’s strategic depth, featuring a decisive goal by Lionel Messi in the 78th minute and a late game-saving play by the goalkeeper. It integrates generated, but realistic, quotes based on player profiles and past interviews, adding a personal and insightful touch to the narrative.
:::
#### Outcome
The result is a rich, comprehensive sports article that not only details Argentina’s thrilling victory but also conveys the vibrant atmosphere of the Copa America final. This seamless integration of KaibanJS tools accelerates the reporting process and elevates the quality of the content delivered to sports enthusiasts around the globe.
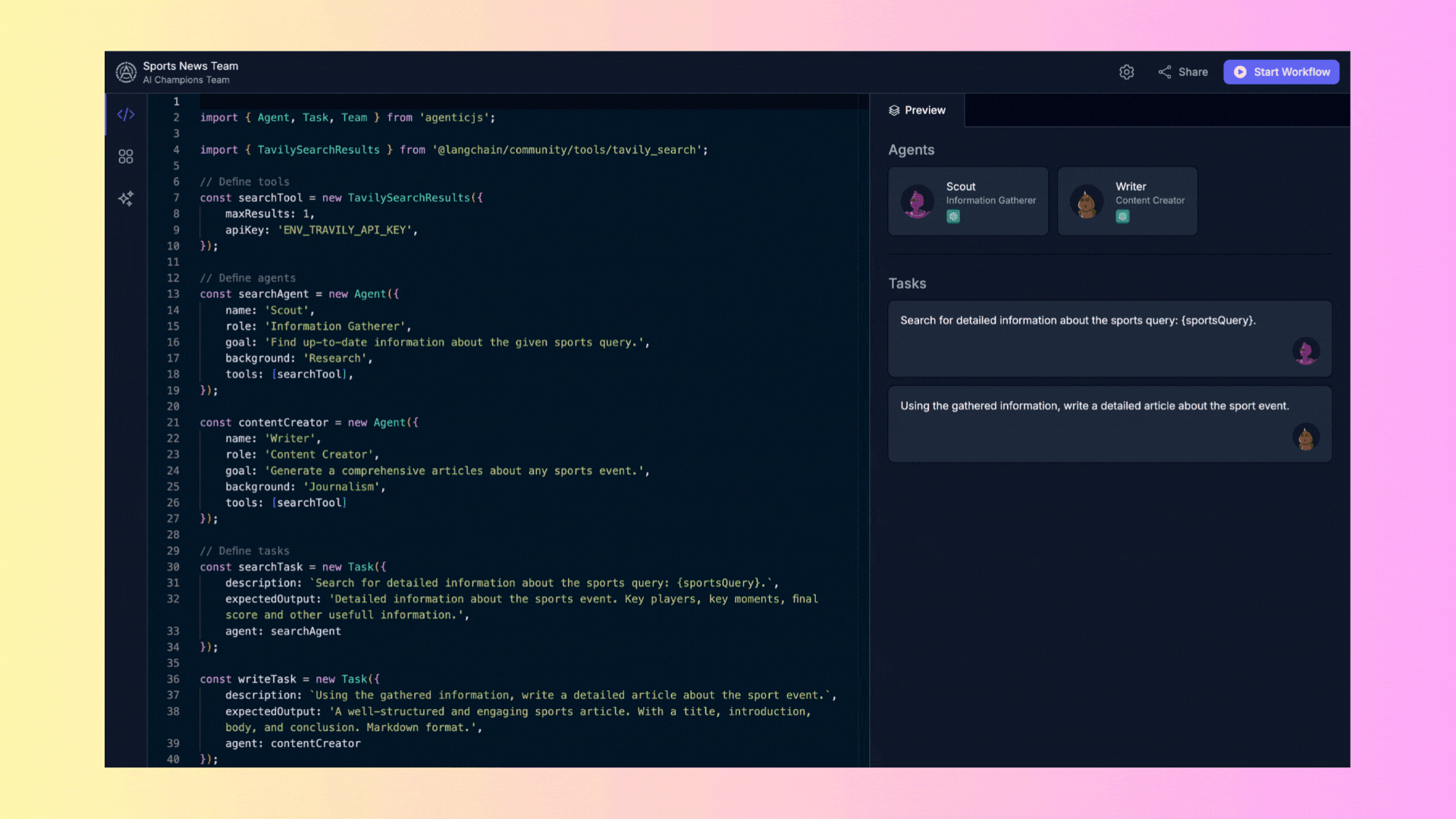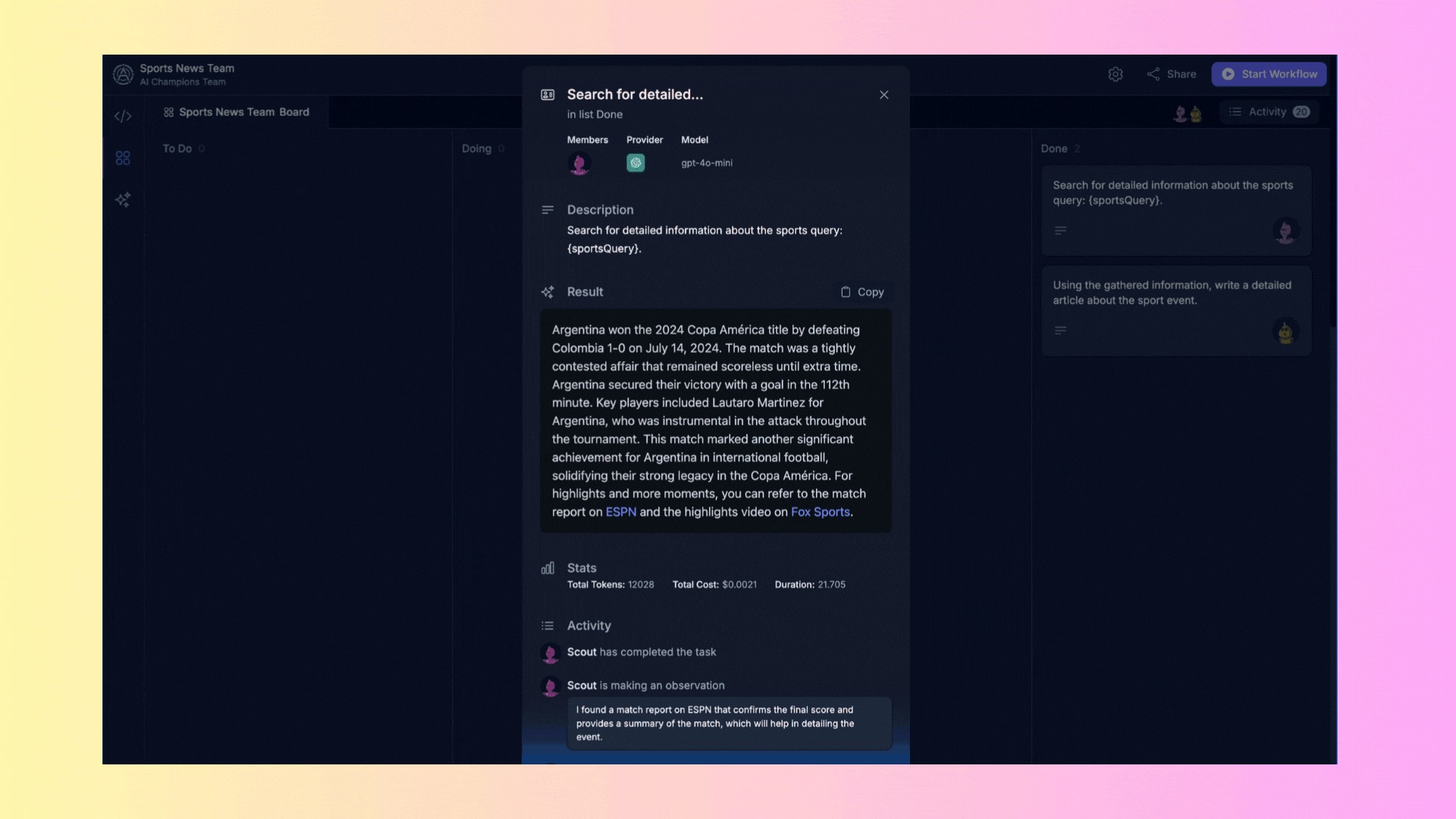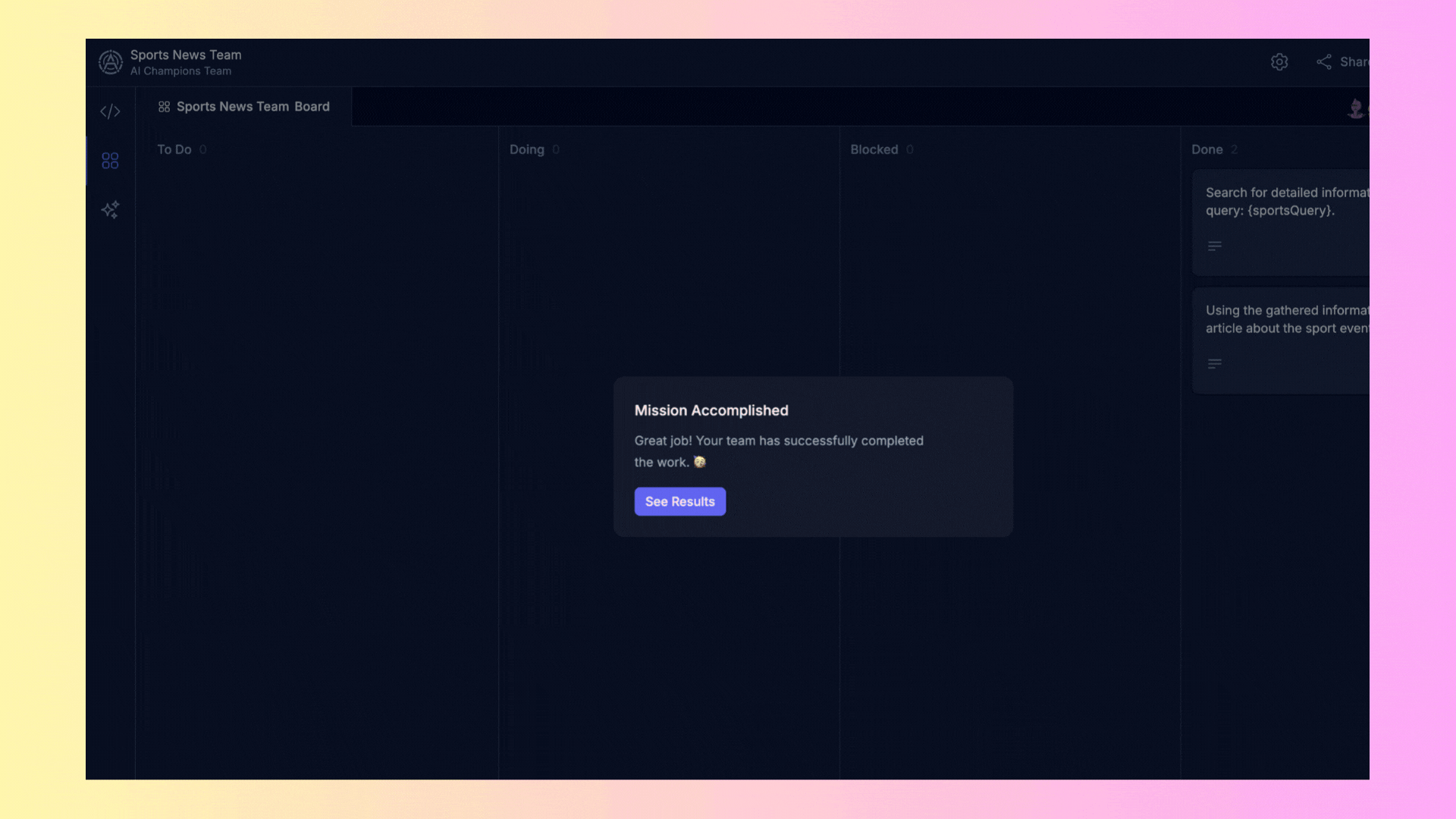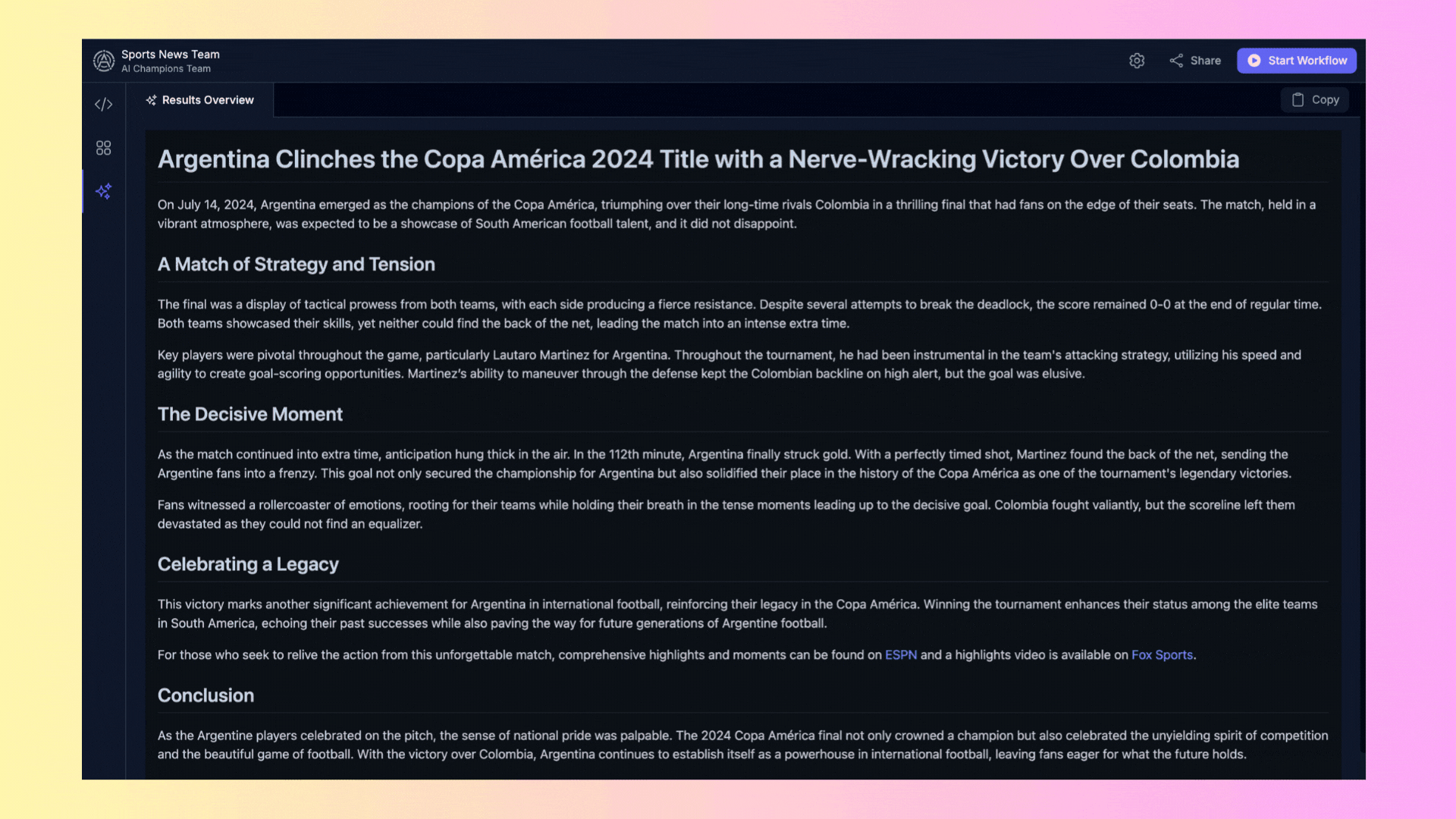
By leveraging KaibanJS and its suite of automated capabilities, media outlets can ensure that they are not just keeping up but leading the way in sports journalism, providing richer, faster, and more accurate coverage than ever before.
### Expected Benefits
- **Timely Reporting**: Automated information gathering and content creation ensure that news is delivered quickly, keeping audiences informed in real-time.
- **High-Quality Content**: The specialized roles of agents and the use of advanced tools lead to the production of well-researched and structured articles, enhancing the quality of the content.
- **Scalability**: This solution allows for the scaling of sports news coverage, enabling multiple sports events to be reported on simultaneously without the need for additional human resources.
- **Cost Efficiency**: By automating the content creation process, organizations can significantly reduce the costs associated with traditional journalism workflows.
Ready to revolutionize your sports news reporting process? Dive deeper into KaibanJS and explore the endless possibilities it offers. For more information, check out our [website](https://www.kaibanjs.com) and [community](https://www.kaibanjs.com/discord).
:::info[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/use-cases/02-Trip Planning.md
//--------------------------------------------
// File: ./src/use-cases/02-Trip Planning.md
//--------------------------------------------
---
title: Trip Planning
description: Discover how KaibanJS can transform trip planning with intelligent agents that analyze, recommend, and create detailed travel itineraries. Learn how our tools can tailor travel plans to personal preferences and local insights, enhancing the travel experience with efficiency and precision.
---
In the dynamic world of travel planning, creating personalized and detailed itineraries demands not only an understanding of the destination but also the ability to adapt to travelers' preferences and local nuances. Traditional methods often rely heavily on manual research and planning, which can be time-consuming and less precise.
VIDEO
:::tip[Try it Out in the Playground!]
Curious about how this solution comes together? Explore it interactively in our playground before getting into the details. [Try it now!](https://www.kaibanjs.com/share/IeeoriFq3uIXlLkBjXbl)
:::
### Traditional Approach Challenges
:::challenges
When planning trips, travel agents and individuals typically go through a labor-intensive process. Here’s a snapshot of the traditional steps involved:
1. **City Selection:** Analysts pore over multiple data sources to recommend the best city based on weather, seasonal events, and travel costs.
2. **Local Insights:** Gaining authentic insights about the city requires contacting local experts or extensive online research to understand attractions and customs.
3. **Itinerary Planning:** Constructing a detailed travel plan involves curating daily activities, dining options, and accommodations, often needing revisions to fit within budget constraints or schedule changes.
*Note: While this use case focuses on automating the selection and initial planning stages, some elements like real-time adjustments during the trip remain manual.*
:::
### The Agentic Solution
Imagine simplifying this complex process with KaibanJS automation:
- **Scenario:** Planning a cultural trip from New York to cities like Tokyo, Paris, or Berlin between December 1st and 15th, 2024, focusing on art and culture.
Before diving into the automated process, let's meet the **key Agents** tasked with revolutionizing trip planning:
:::agents
**Peter Atlas, the City Selector Agent:** With expertise in travel data analysis, Peter uses real-time data to select the ideal destination based on comprehensive criteria including weather conditions and local events.
**Sophia Lore, the Local Expert Agent:** Sophia provides in-depth knowledge of the selected city, compiling a guide that includes must-see attractions, local customs, and special events that align with the traveler’s interests.
**Maxwell Journey, the Amazing Travel Concierge:** Maxwell crafts detailed itineraries that include daily activities, dining suggestions, and packing lists, tailored to ensure an unforgettable travel experience within the traveler’s budget.
:::
#### Process Overview
With the agents introduced, here’s how they collaborate to deliver a seamless travel planning experience:
:::tasks
1. **Automated City Selection:** Peter Atlas evaluates potential cities and selects the most suitable destination based on the specified dates and cultural interests.
2. **In-depth Local Insights:** Sophia Lore gathers extensive details about the chosen city, providing a rich cultural guide that enhances the travel experience.
3. **Itinerary Development:** Maxwell Journey designs a comprehensive 7-day itinerary that includes cultural visits, culinary experiences, and all necessary travel logistics formatted neatly in markdown.
:::
#### Outcome
The result is a meticulously planned cultural journey that not only meets but exceeds the expectations of the discerning traveler. This integration of KaibanJS tools streamlines the planning process and elevates the quality of travel itineraries delivered to globetrotters.
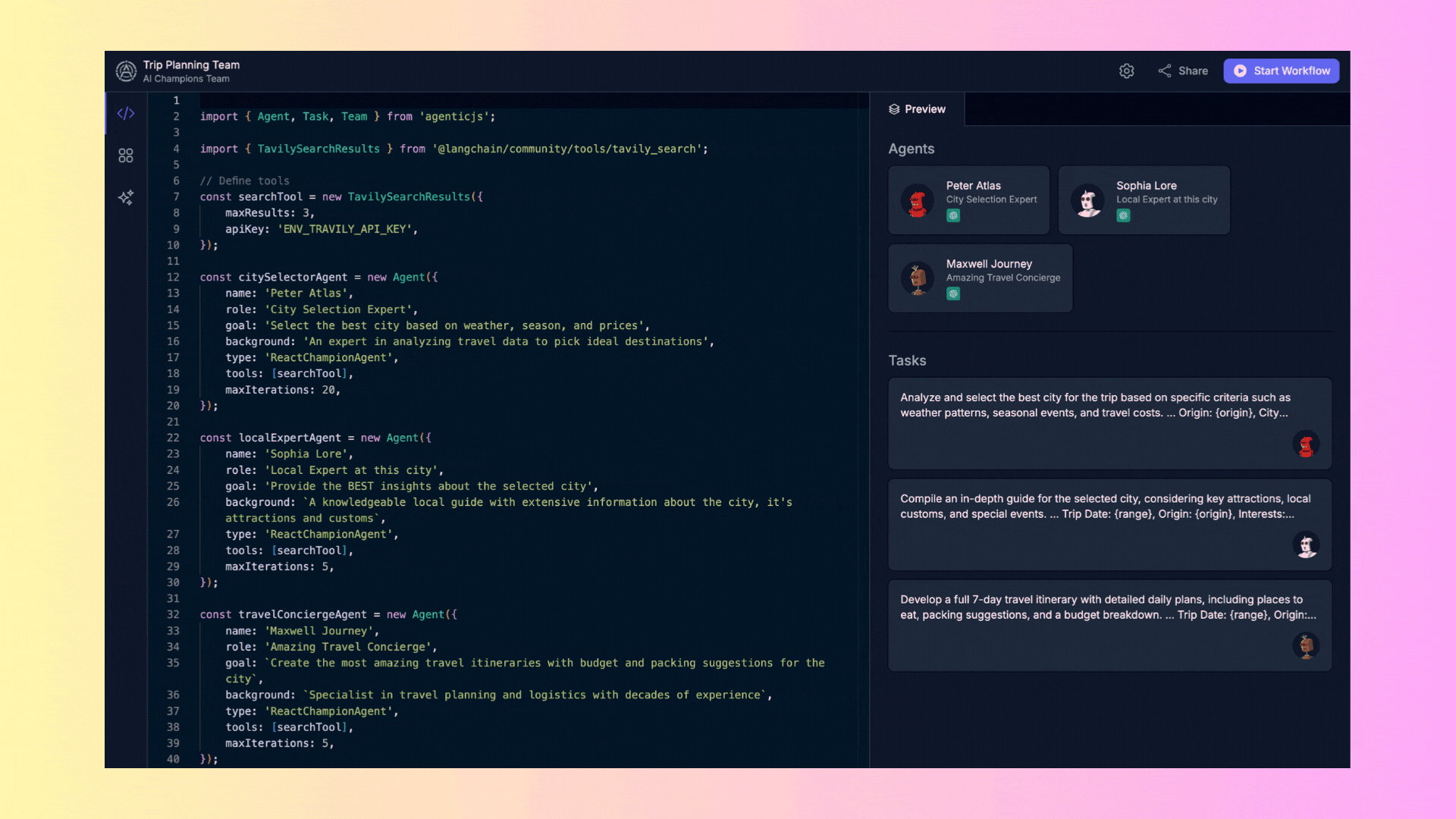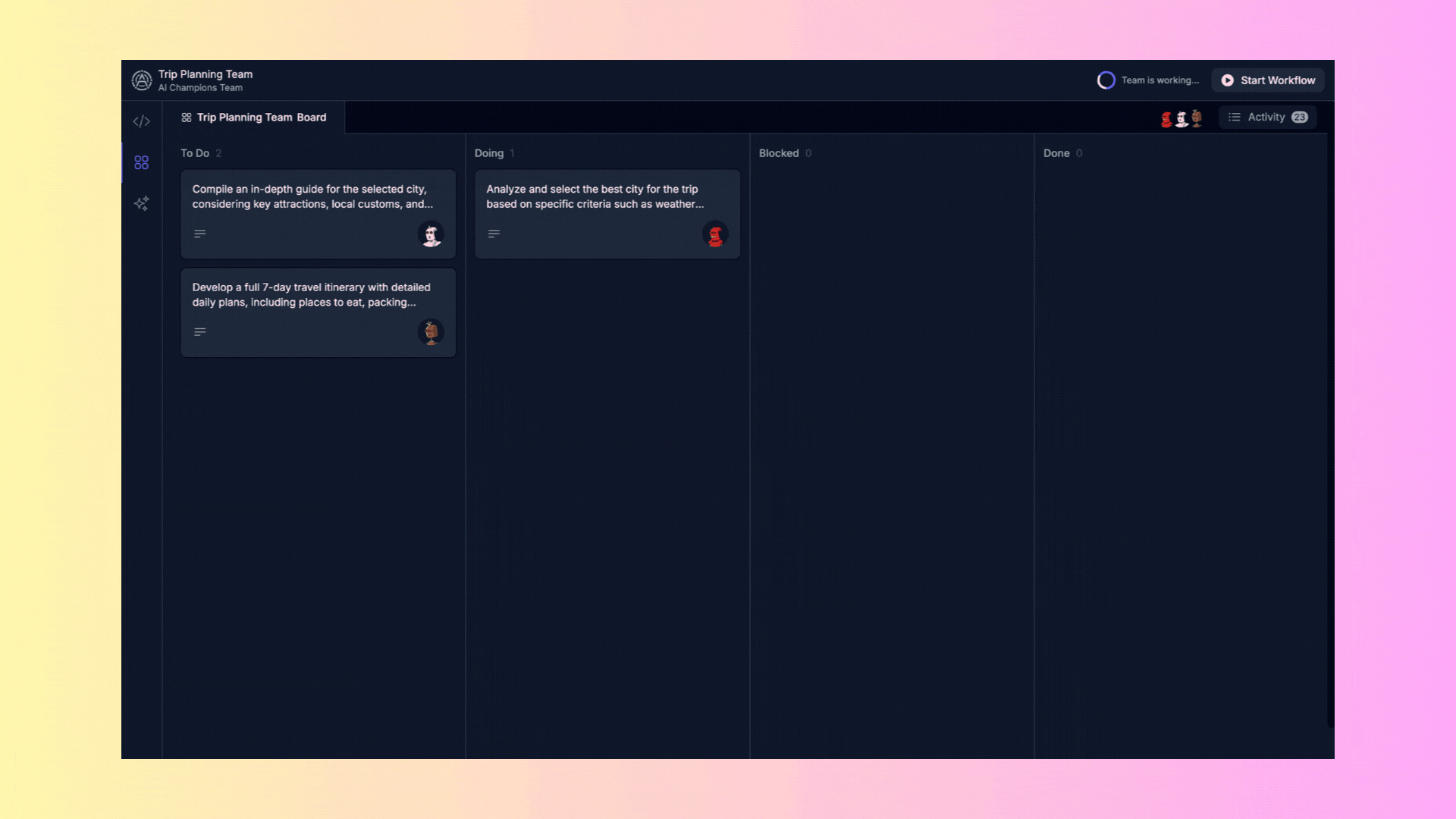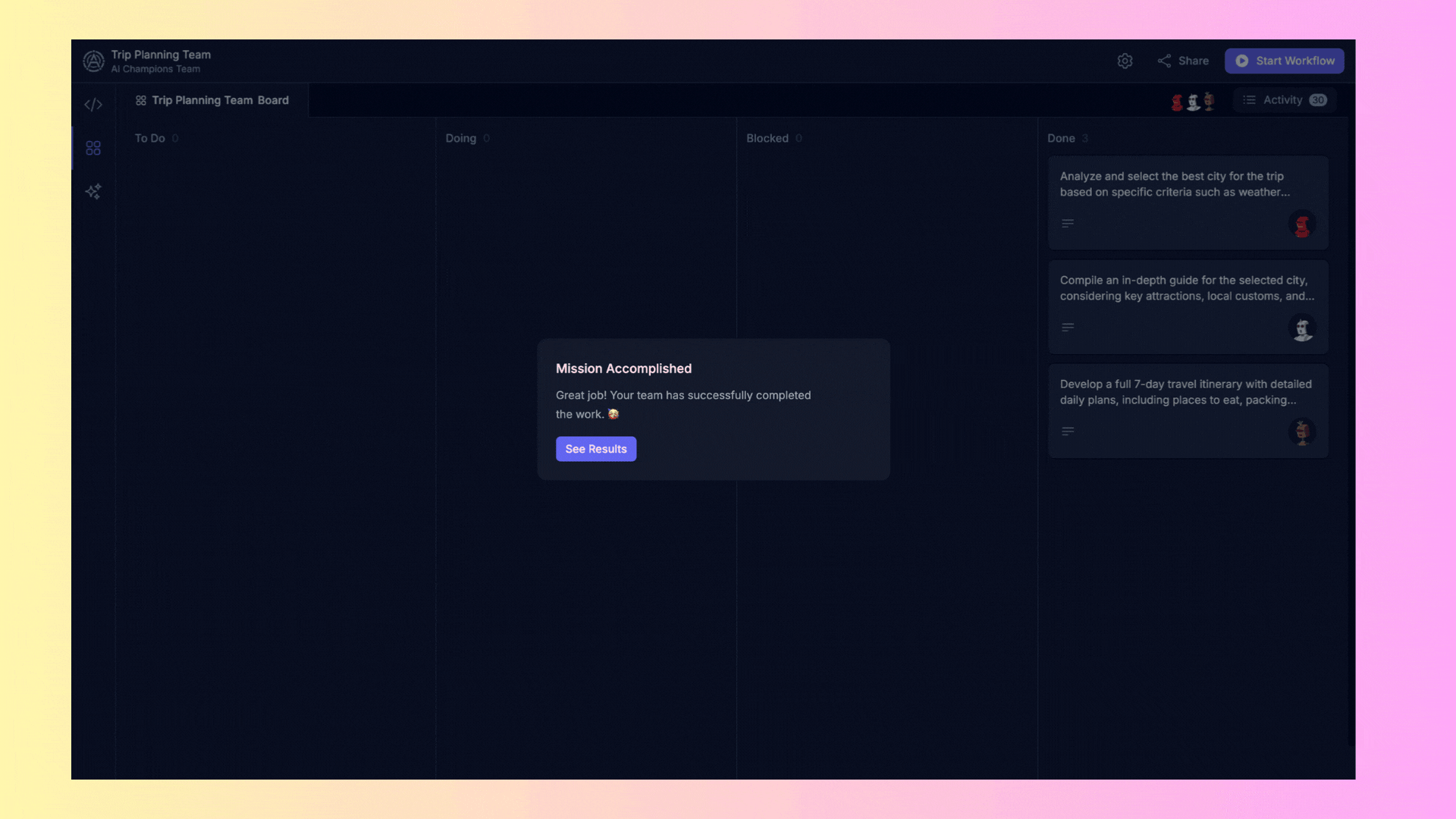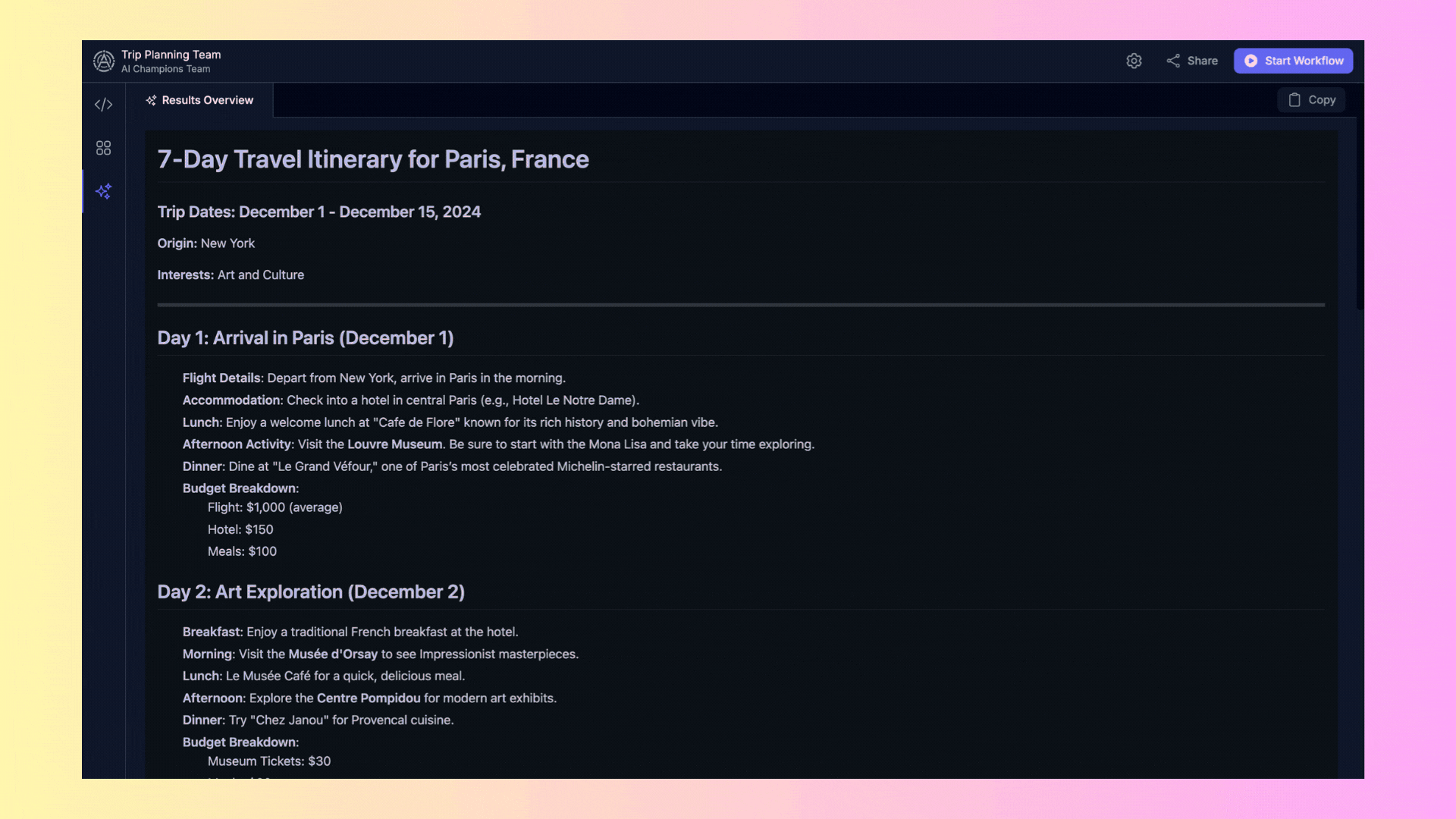
By leveraging KaibanJS and its suite of intelligent agents, travel agencies and individuals can transform the way they plan trips, offering more personalized and engaging travel experiences with significantly reduced effort and increased accuracy.
### Expected Benefits
- **Personalized Recommendations:** Automated tools tailor city selections and itineraries to match personal interests and preferences, enhancing satisfaction.
- **Efficient Planning:** Streamline the planning process, reducing the time spent on manual research and adjustments.
- **Rich Local Insights:** Gain authentic local knowledge quickly, enriching the travel experience with genuine cultural immersion.
- **Cost-Effective Itineraries:** Optimize travel budgets by intelligently suggesting activities and logistics that offer the best value for money.
Ready to revolutionize your trip planning process? Dive deeper into KaibanJS and explore the endless possibilities it offers. For more information, check out our [website](https://www.kaibanjs.com) and [community](https://www.kaibanjs.com/discord).
:::info[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/use-cases/03-Resume Creation.md
//--------------------------------------------
// File: ./src/use-cases/03-Resume Creation.md
//--------------------------------------------
---
title: Resume Creation
description: Discover how KaibanJS can revolutionize the resume creation process with intelligent agents that analyze conversational input and craft compelling resumes. Learn how our tools can tailor resumes to highlight job seekers' qualifications and achievements, enhancing their prospects in the job market.
---
In today's competitive job market, crafting a resume that stands out is crucial. Traditional methods of resume creation often involve manual data entry and formatting, which can be time-consuming and prone to errors.
VIDEO
:::tip[Try it Out in the Playground!]
Curious about how this solution comes together? Explore it interactively in our playground before getting into the details. [Try it now!](https://www.kaibanjs.com/share/f3Ek9X5dEWnvA3UVgKUQ)
:::
### Traditional Approach Challenges
:::challenges
Typically, individuals manually compile their work history, skills, and educational background into a format that they hope will catch the eye of recruiters. This process includes:
1. **Information Gathering:** Manually collecting and organizing personal information, job history, skills, and education.
2. **Formatting:** Trying to format the resume in a way that is both attractive and professional without consistent guidelines.
3. **Content Writing:** Writing and rewriting content to ensure it is concise, compelling, and relevant to job applications.
4. **Proofreading and Editing:** Ensuring the resume is free from errors and polished to a professional standard.
*Note: In this use case, we focus on automating the extraction of structured information and the subsequent resume writing, which are typically manual and time-intensive tasks. These steps are typically manual and time-intensive, and while our solution automates the initial creation, tailoring resumes to specific job applications remains a critical aspect where human input is invaluable.*
:::
### The Agentic Solution
Imagine transforming this process with KaibanJS automation:
- **Scenario:** Creating a resume for David Llaca, a JavaScript Developer who is currently exploring new job opportunities.
Before diving into the process, let's introduce the **key Agents** involved in transforming resume creation:
:::agents
**Mary, the Profile Analyst:** Specializes in extracting structured information from conversational user inputs, ensuring all relevant details are captured efficiently and accurately.
**Alex Mercer, the Resume Writer:** Uses the structured data to craft resumes that are not only well-organized but also designed to highlight the candidate's qualifications and attract potential employers' attention.
:::
#### Process Overview
With the agents introduced, here’s how they collaborate to deliver a seamless resume creation experience:
:::tasks
1. **Data Extraction:** Mary, the Profile Analyst, processes David's input about his career and educational background, extracting key information like job titles, skills, and experiences.
2. **Resume Crafting:** Utilizing the structured data, Alex Mercer, the Resume Writer, creates a detailed and attractive resume. This document includes a personal summary, a detailed work experience section, a list of skills, and educational achievements, all formatted to professional standards.
:::
#### Outcome
The result is a meticulously crafted resume for David that effectively showcases his skills and experiences in JavaScript development. This resume is ready to be submitted to potential employers, significantly enhancing his job application process.
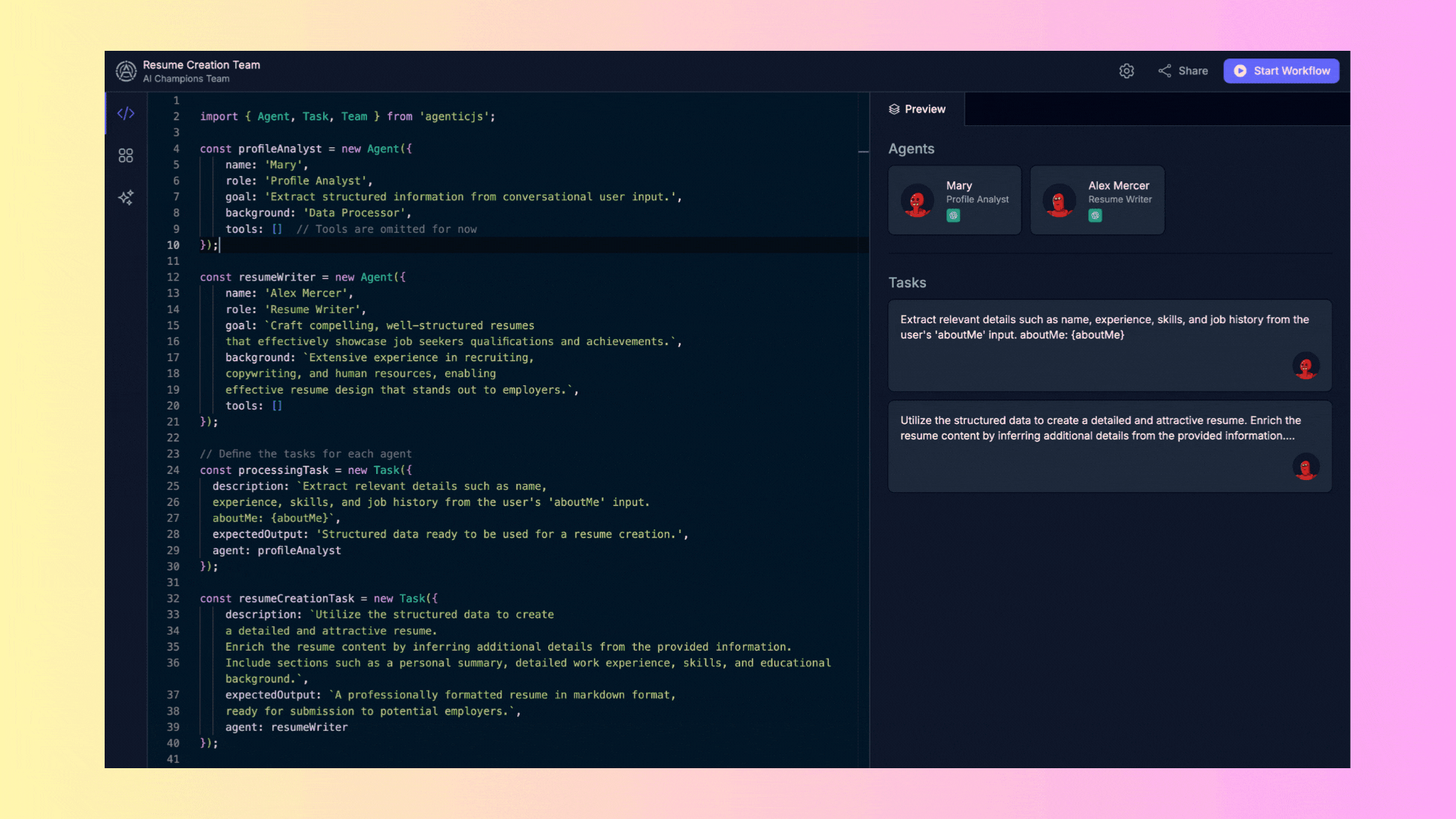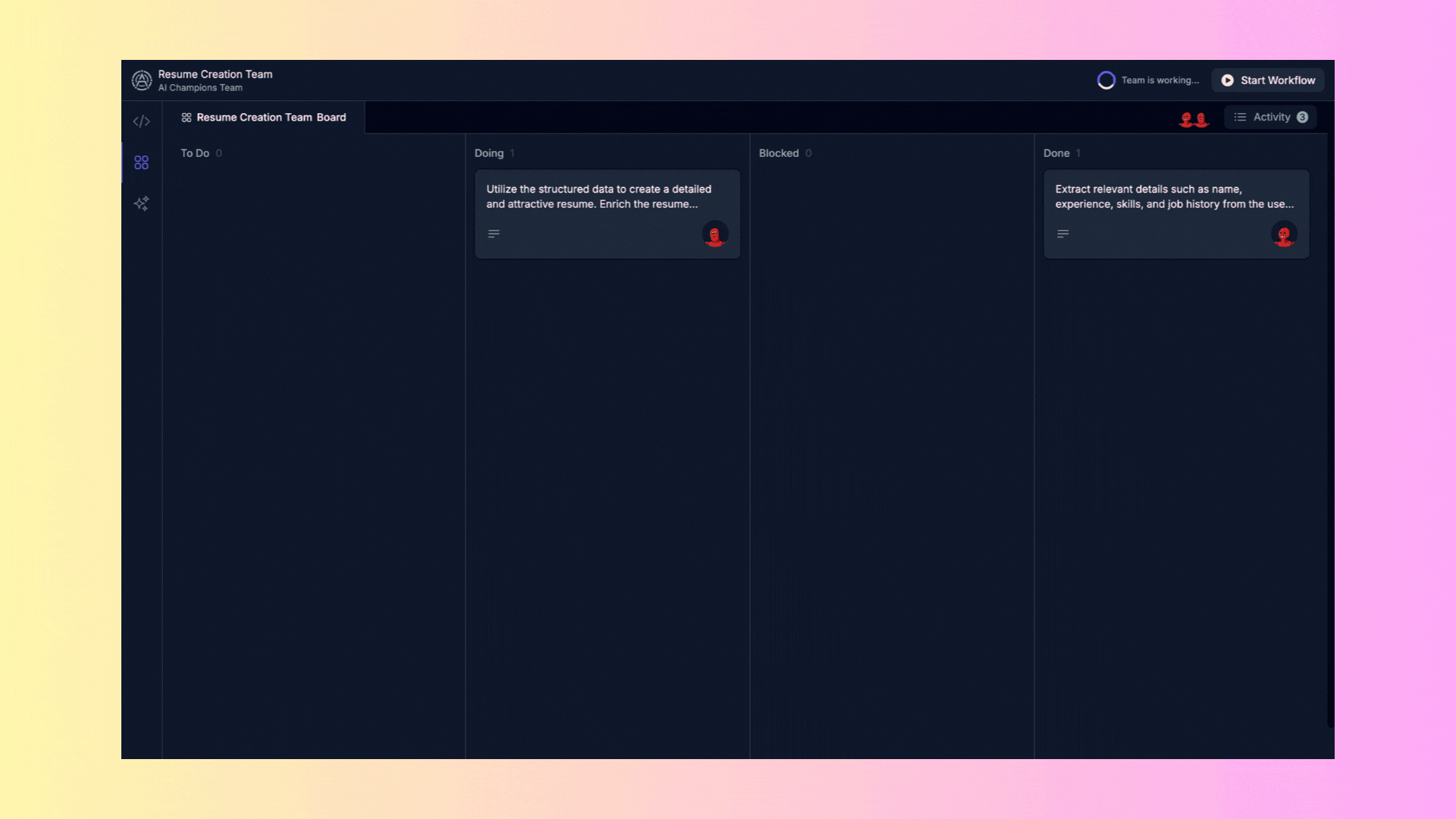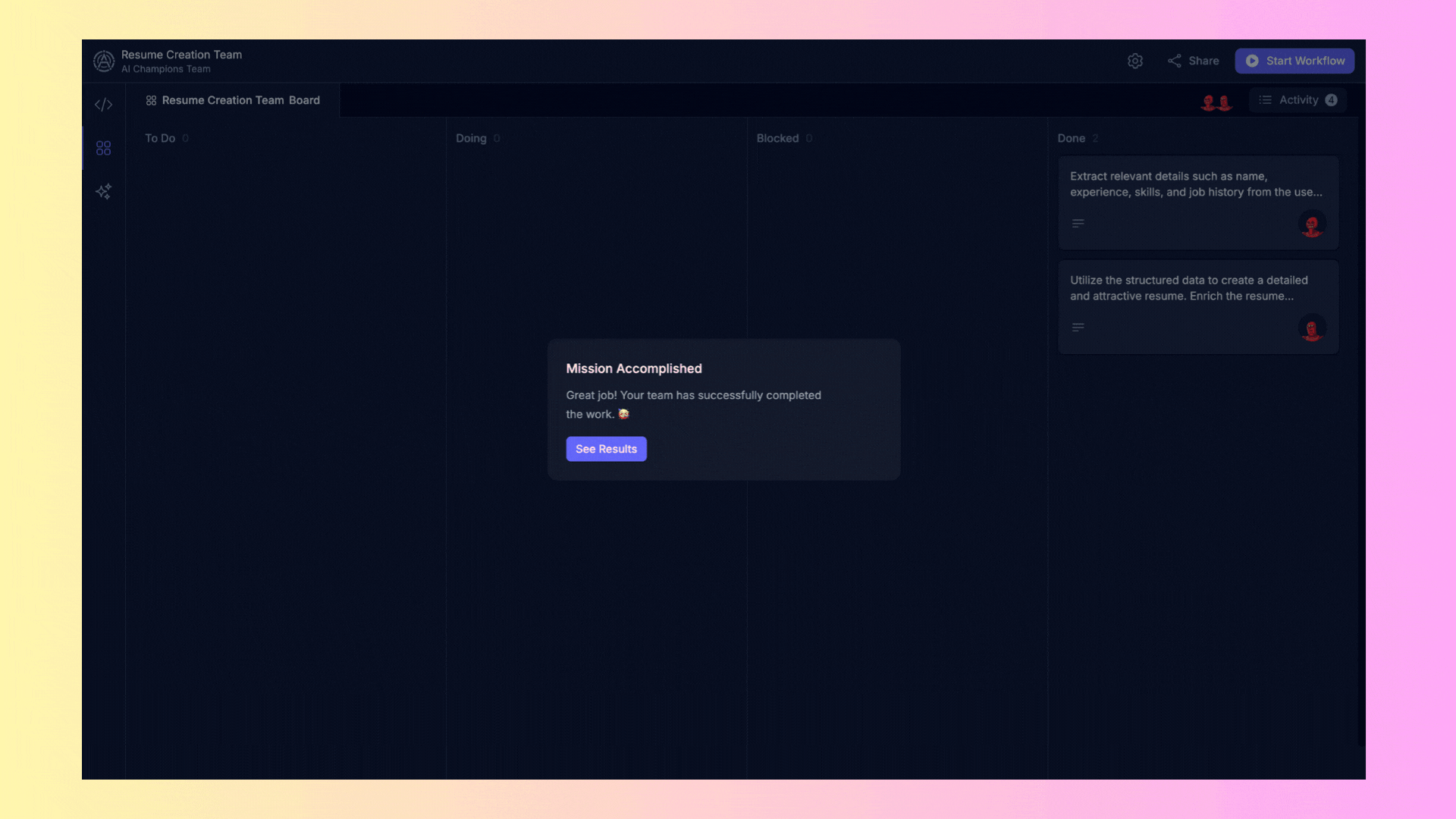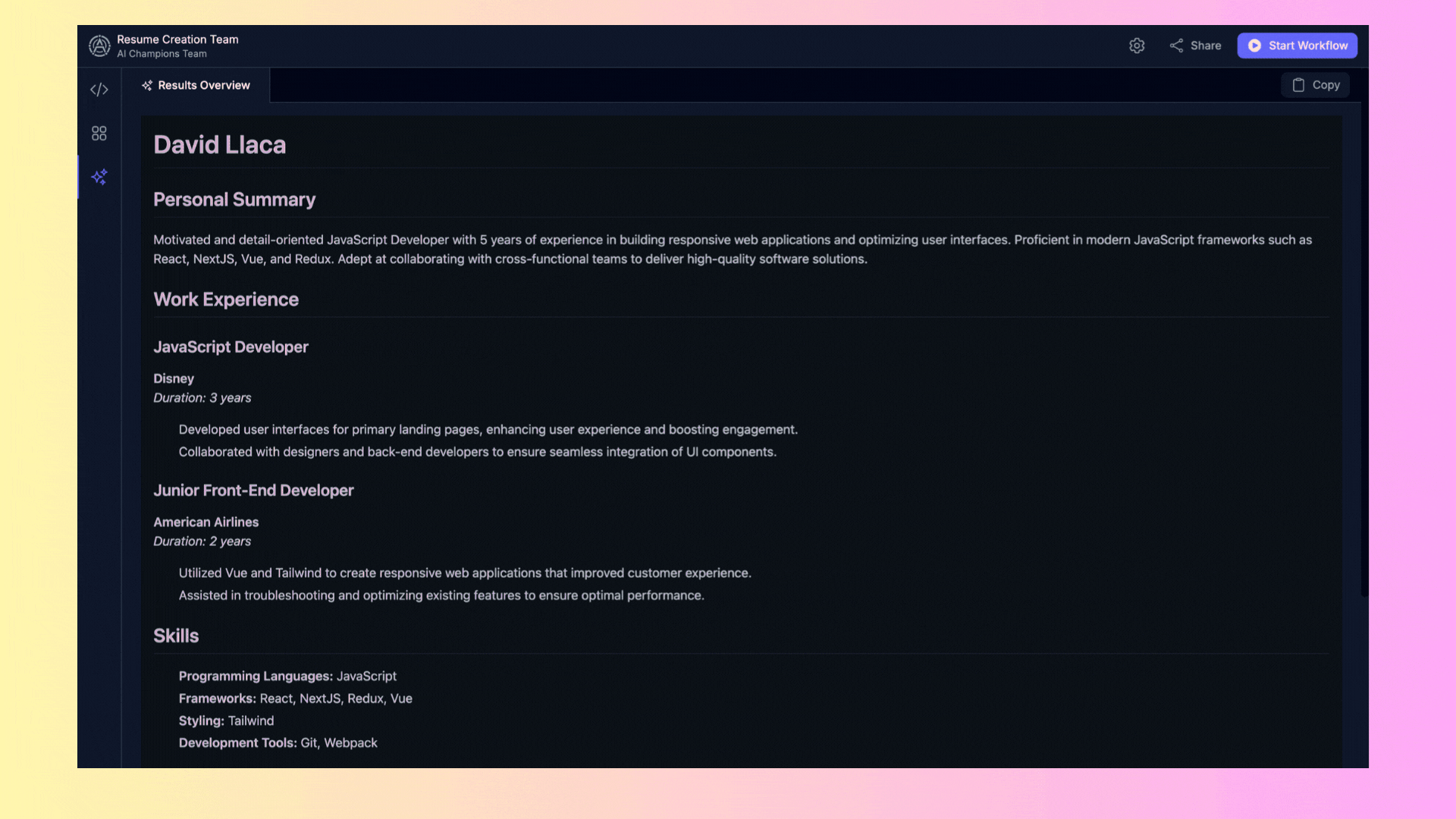
By leveraging KaibanJS and its intelligent agents, job seekers can transform the way they create resumes, making the process more streamlined, efficient, and effective at capturing the attention of potential employers.
### Expected Benefits
- **Efficiency:** Automates the time-consuming process of data extraction and resume formatting.
- **Precision:** Ensures that all relevant information is accurately captured and beautifully presented.
- **Professional Appeal:** Creates resumes that are structured and formatted to meet professional standards, increasing the chances of job application success.
Ready to revolutionize your resume creation process? Dive deeper into KaibanJS and explore the endless possibilities it offers. For more information, check out our [website](https://www.kaibanjs.com) and [community](https://www.kaibanjs.com/discord).
:::info[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/use-cases/04-Company Research.md
//--------------------------------------------
// File: ./src/use-cases/04-Company Research.md
//--------------------------------------------
---
title: Company Research
description: Learn how KaibanJS facilitates thorough and detailed company research by deploying intelligent agents capable of analyzing various aspects of a business. Discover how our tools can streamline the process of gathering data on business models, funding history, operational efficiencies, and more, enhancing business insights and decision-making.
---
VIDEO
:::tip[Try it Out in the Playground!]
Curious about how this solution comes together? Explore it interactively in our playground before getting into the details. [Try it now!](https://www.kaibanjs.com/share/08EYaQG4mRmYbU5jftXA)
:::
It’s Saturday afternoon, and here I am, nearly four hours deep into researching companies like ours. So far, I've only managed to fully analyze two companies. It’s frustrating. With each passing hour, I’m reminded just how slow and piecemeal this traditional research process can be.
I’m gearing up for a crucial meeting with our advisors next week, and I need to bring my A-game.
**That’s when it hit me—why not use our own creation, KaibanJS, to streamline this?**
It's the perfect scenario to "eat our own dog food" and really put our platform to the test. I can't believe I didn’t think of this sooner, sticking to the old, manual ways of doing things.
Manual research is not just time-consuming; it's overwhelming. It involves digging through disparate data sources, which often results in incomplete insights. Each hour spent manually correlating data is an hour not spent on strategic analysis or decision-making.
### Traditional Approach Challenges
:::challenges
Conducting comprehensive company research typically includes several labor-intensive steps:
1. **Business Model Analysis:** Analysts manually search for information regarding the company’s revenue sources and scalability.
2. **Funding Research:** Gathering detailed data on a company’s funding rounds and investors requires access to financial databases and reports.
3. **Operational Insights:** Understanding a company’s operational strategies involves deep dives into internal processes and infrastructure, often requiring firsthand interviews or extensive document reviews.
4. **Exit Strategy Exploration:** Analyzing a company’s past exits and future plans necessitates historical data comparison and strategy evaluation.
5. **Market Position Assessment:** Determining a company’s market segmentation and brand strength involves analyzing market data and competitor performance.
6. **Customer Acquisition Studies:** Investigating effective customer acquisition channels and strategies requires data on marketing approaches and outcomes.
*Note: This use case automates the collection and analysis of data across these areas to produce a cohesive and comprehensive view of the company, traditionally done through manual research.*
:::
### The Agentic Solution
Imagine transforming this complex research process with KaibanJS automation:
- **Scenario:** Conducting in-depth research on the company Vercel.
Before diving into the process, let’s meet the **key Agents** involved in transforming company research:
:::agents
**Business Model Analyst, Funding Specialist, Operations Analyst, Exit Strategy Advisor, Market Analyst, Acquisition Strategist, and Report Compiler:** Each agent is equipped with specialized tools and goals, from analyzing business models to compiling comprehensive reports, ensuring that all aspects of company research are thoroughly covered.
:::
#### Process Overview
With the agents introduced, here’s how they collaborate to deliver seamless and integrated company research:
:::tasks
1. **Business Model Analysis:** The Business Model Analyst extracts key information about Vercel’s revenue streams and scalability potential.
2. **Funding Research:** The Funding Specialist gathers detailed historical data on funding rounds and investor engagements.
3. **Operational Insights:** The Operations Analyst reviews Vercel’s infrastructure and operational strategies for efficiency gains.
4. **Exit Strategy Exploration:** The Exit Strategy Advisor examines past and potential future exits to outline strategic recommendations.
5. **Market Position Assessment:** The Market Analyst assesses Vercel’s standing in the market against competitors and industry trends.
6. **Customer Acquisition Analysis:** The Acquisition Strategist analyzes the effectiveness of various customer acquisition channels and strategies.
7. **Comprehensive Reporting:** Finally, the Report Compiler synthesizes all gathered data into a detailed report that offers a panoramic view of Vercel’s business landscape.
:::
#### Outcome
The result is an exhaustive and meticulously prepared report that not only aggregates all pertinent data about Vercel but also provides actionable insights and strategic recommendations. This enhanced method of company research facilitates informed decision-making and strategic planning.

By leveraging KaibanJS and its intelligent agents, businesses and analysts can revolutionize the way they conduct company research, achieving greater depth and breadth in their analyses with significantly reduced effort and increased accuracy.
### Expected Benefits
- **Depth of Insight:** Provides comprehensive analyses across multiple dimensions of a company’s operations.
- **Efficiency:** Reduces the time and resources required to gather and analyze complex data.
- **Accuracy:** Enhances the accuracy of business insights through systematic data collection and analysis.
- **Strategic Impact:** Offers strategic recommendations based on thorough and integrated research findings.
Ready to revolutionize your company research processes? Dive deeper into KaibanJS and explore the endless possibilities it offers. For more information, check out our [website](https://www.kaibanjs.com) and [community](https://www.kaibanjs.com/discord).
:::info[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/use-cases/05-Hardware Optimization for PC Games.md
//--------------------------------------------
// File: ./src/use-cases/05-Hardware Optimization for PC Games.md
//--------------------------------------------
---
title: Hardware Optimization for PC Games
description: Learn how to optimize PC hardware configurations for running games efficiently with KaibanJS. Discover the best CPU, GPU, and RAM combinations for your game, ensuring optimal performance and cost-effectiveness.
---
In the world of PC gaming, ensuring that a game runs smoothly and efficiently requires careful selection of hardware components. Traditionally, gamers and tech enthusiasts spend considerable time researching different CPUs, GPUs, and RAM configurations, comparing prices, and balancing performance with budget constraints.
VIDEO
:::tip[Try it Out in the Playground!]
Curious about how this solution comes together? Explore it interactively in our playground before getting into the details. [Try it now!](https://www.kaibanjs.com/share/kPvBw88uBiV3utaiRdDK)
:::
### Traditional Approach Challenges
:::challenges
When optimizing hardware for PC gaming, enthusiasts typically follow a detailed, manual process. Below is an outline of the typical steps involved, highlighted for emphasis:
1. **Researching Hardware Options:** Users manually search for the best CPUs, GPUs, and RAM configurations across multiple websites, forums, and review sites.
2. **Price Comparison:** Gathering and comparing prices from different retailers to find the best deals for each component.
3. **Balancing Performance and Cost:** Evaluating different combinations of hardware to find the optimal setup that balances high performance with a reasonable budget.
4. **Final Decision and Purchase:** After extensive research, users decide on the components and proceed with the purchase.
*Note: In this use case, the purchasing step is not currently automated by KaibanJS to maintain simplicity in the workflow.*
:::
### The Agentic Solution
Now, imagine this scenario optimized with KaibanJS automation:
- **Game:** Cyberpunk 2077
- **Query:** "What are the best hardware setups to run Cyberpunk 2077?"
Before diving into the process, let's understand the roles of the **key Agents** involved:
:::agents
**CPU Analyst:** This agent is responsible for analyzing the CPU requirements. It identifies and compares the best CPU options for running the game efficiently, using real-time data on performance benchmarks.
**GPU Specialist:** After identifying suitable CPUs, the GPU Specialist takes over, researching and comparing the best graphics card options to achieve optimal game performance. This agent focuses on ensuring the game runs smoothly at high settings.
**RAM Analyst:** This agent analyzes the RAM requirements, identifying the optimal configurations that will provide smooth gameplay without unnecessary overhead or bottlenecks.
**Price Analyst:** Once the hardware options are identified, the Price Analyst gathers current market prices for each component, ensuring that the best deals are considered in the final recommendation.
**Combination Evaluator:** Finally, the Combination Evaluator analyzes different combinations of CPU, GPU, and RAM to determine the top three setups. This agent balances performance and cost, providing the best options for the user.
:::
#### Process Overview
Now that you are familiar with the agents and their roles, let's explore the process they follow to transform raw data into actionable recommendations.
:::tasks
1. **CPU Analysis:** The CPU Analyst searches for information on the best CPUs for running Cyberpunk 2077, considering factors like clock speed, core count, and thermal performance. The agent provides a detailed report with top CPU options and benchmarks.
2. **GPU Analysis:** The GPU Specialist identifies the best graphics cards available that can handle Cyberpunk 2077 at high settings, providing performance metrics and comparisons.
3. **RAM Analysis:** The RAM Analyst evaluates various RAM configurations to ensure smooth gameplay, focusing on capacity, speed, and latency.
4. **Price Comparison:** The Price Analyst gathers up-to-date pricing information for the recommended CPUs, GPUs, and RAM, comparing prices from various retailers.
5. **Combination Evaluation:** The Combination Evaluator analyzes and recommends the top three hardware combinations for running Cyberpunk 2077, balancing performance with cost-effectiveness.
:::
#### Outcome
The result is a comprehensive report detailing the top three hardware setups for running Cyberpunk 2077 efficiently. The report includes specific CPU, GPU, and RAM combinations along with current prices, allowing gamers to make informed decisions without the need for extensive manual research.

By leveraging KaibanJS and its suite of automated capabilities, gamers and tech enthusiasts can optimize their PC builds more efficiently, ensuring they get the best performance possible for their budget.
### Expected Benefits
- **Time Efficiency:** Automated hardware research and price comparison reduce the time users spend on manual searches, delivering quick and accurate recommendations.
- **Optimized Performance:** The use of specialized agents ensures that the recommended hardware combinations offer the best possible performance for the selected game.
- **Cost-Effective Solutions:** The price comparison feature ensures that users get the best value for their money, balancing performance with budget constraints.
- **Personalized Recommendations:** The process tailors hardware suggestions to specific games, ensuring optimal performance based on the unique demands of each title.
Ready to optimize your gaming setup? Dive deeper into KaibanJS and explore the endless possibilities it offers. For more information, check out our [website](https://www.kaibanjs.com) and [community](https://www.kaibanjs.com/discord).
:::info[We Love Feedback!]
Is there something unclear or quirky in the docs? Maybe you have a suggestion or spotted an issue? Help us refine and enhance our documentation by [submitting an issue on GitHub](https://github.com/kaiban-ai/KaibanJS/issues). We’re all ears!
:::
### ./src/use-cases/06-GitHub-Release-Social-Media-Team.md
//--------------------------------------------
// File: ./src/use-cases/06-GitHub-Release-Social-Media-Team.md
//--------------------------------------------
---
title: GitHub Release Social Media Team
description: KaibanJS showcases the power of autonomous agents and agentic AI in action. Built with our advanced agent framework, this specialized team of AI agents transforms GitHub release notes into engaging social media content. Experience true agent autonomy as they collaborate to generate tweets, LinkedIn posts, blog articles, and Discord announcements with minimal human intervention.
---
Announcing software releases across social media platforms can be challenging. KaibanJS simplifies this by using autonomous agents to automatically transform GitHub release notes into engaging tweets, LinkedIn posts, blog articles, and Discord announcements - saving time while maintaining consistent messaging across all channels.
:::tip[Try it Out in the Playground!]
Curious about how this solution comes together? Explore it interactively in our playground before getting into the details. [Try it now!](https://www.kaibanjs.com/share/RNrmzWds1MpHJEANyymJ)
:::
### The Challenge
Announcing product updates often requires creating promotional content tailored for multiple platforms, such as:
- **Tweets** for X (Twitter) that are concise yet impactful.
- **LinkedIn posts** that are professional and engaging.
- **Blog articles** that provide in-depth insights.
- **Discord announcements** that excite and inform the community.
Manually drafting, refining, and aligning these pieces can be time-consuming and prone to inconsistencies, especially when updates need to be released quickly.
### The Solution with KaibanJS
KaibanJS solves this problem with an automated workflow using intelligent agents. This process enables teams to create polished content for different platforms based on a single input containing the product name, release notes URL, GitHub repository link, and community link.

### Traditional Approach Challenges
:::challenges
Creating release announcements traditionally involves:
1. **Manual Drafting:** Writing individual posts for each platform requires significant effort.
2. **Content Review:** Ensuring tone consistency and quality involves multiple rounds of edits.
3. **Formatting Adjustments:** Customizing format and style for each platform increases complexity.
4. **Coordination:** Gathering inputs from multiple stakeholders often causes delays.
5. **Scalability Issues:** Repeating this process for frequent updates can overwhelm teams.
KaibanJS eliminates these bottlenecks through intelligent task automation and agent collaboration.
:::
### The Agentic Solution
KaibanJS leverages a team of specialized agents, each focusing on a critical aspect of content creation to ensure seamless automation:
:::agents
- **ContentExtractor:** Responsible for analyzing the provided release notes, this agent identifies key updates, new features, and enhancements. It structures the extracted information to be clear and easily reusable for different platforms.
- **TweetComposer and Evaluator:** These agents generate and refine concise, engaging tweets. The composer drafts multiple tweet options, while the evaluator ensures clarity, proper tone, and adherence to formatting guidelines like hashtags and emojis.
- **LinkedInPostComposer and Evaluator:** The LinkedIn agents create and polish professional posts that highlight key features and use cases. They focus on maintaining an engaging and informative tone suitable for a professional audience.
- **DiscordCopyComposer and Evaluator:** These agents develop community-friendly announcements tailored for Discord. They ensure enthusiasm, clarity, and proper Markdown formatting to enhance readability.
- **BlogPostComposer and Evaluator:** Focused on long-form content, these agents draft detailed, SEO-optimized blog posts. The evaluator reviews and refines the content to align with platform guidelines and ensure readability and impact.
- **ResultAggregator:** Once all the content is created and refined, this agent compiles the outputs into a single Markdown document, organizing tweets, LinkedIn posts, blog articles, and Discord announcements for easy publication.
:::
### Process Overview
Here’s how KaibanJS agents collaborate to deliver ready-to-publish content:
:::tasks
1. **Content Extraction:** The ContentExtractor analyzes the release notes, summarizing updates, features, and improvements in a structured format.
2. **Tweet Generation:** The TweetComposer creates three variations of tweets focusing on practical benefits, hashtags, and emojis to maximize engagement.
3. **LinkedIn Post Creation:** The LinkedInPostComposer drafts a professional post emphasizing features, use cases, and calls-to-action.
4. **Discord Copy Writing:** The DiscordCopyComposer prepares two announcement variants to share updates in community-friendly language.
5. **Blog Post Writing:** The BlogPostComposer writes an in-depth article explaining the release, providing technical insights, use cases, and examples.
6. **Evaluation and Refinement:** Evaluators for each content type review drafts to ensure clarity, consistency, and optimization for each platform.
7. **Aggregation:** The ResultAggregator compiles all refined outputs into one structured Markdown file, ready for publication.
:::
### Outcome
The final outputs include:
- **Three tweet options** to choose from, each emphasizing different aspects of the release.
- **A LinkedIn post** that is professional, informative, and engaging.
- **Two Discord announcements** optimized for community interaction.
- **A detailed blog post** ready for publishing on platforms like Medium or Hugging Face.
### Expected Benefits
- **Efficiency:** Save hours by automating repetitive content creation tasks.
- **Consistency:** Maintain uniform tone and structure across all platforms.
- **Scalability:** Easily adapt the workflow to handle multiple product updates.
- **Quality Assurance:** Ensure all content is refined and optimized before publishing.
### Get Started Today
Ready to simplify your release content process? Explore KaibanJS and revolutionize the way you manage product updates.
🌐 **Website**: https://www.kaibanjs.com/
💻 **GitHub Repository**: https://github.com/kaiban-ai/KaibanJS
🤝 **Discord Community**: https://kaibanjs.com/discord
---
:::info[We Value Your Feedback!]
Have suggestions or questions about this use case? Join our community or submit an issue on GitHub to help us improve. [Contribute Now](https://github.com/kaiban-ai/KaibanJS/issues)
:::
### ./src/use-cases/07-AI-Driven Reddit Comment Generator.md
//--------------------------------------------
// File: ./src/use-cases/07-AI-Driven Reddit Comment Generator.md
//--------------------------------------------
---
title: AI-Driven Reddit Comment Generator
description: Discover how KaibanJS simplifies the creation of engaging and context-aware comments for Reddit posts. Learn how to generate and refine comments using AI agents in KaibanJS.
---
Creating thoughtful and engaging Reddit comments at scale can be challenging. KaibanJS simplifies this by using autonomous agents to automatically analyze posts, generate relevant responses, and refine comments that resonate with each community - saving time while maintaining authentic and meaningful participation across multiple subreddits.
:::tip[Try it Out in the Playground!]
Curious about how this solution works? Test it interactively in our playground before diving into the details. [Try it now!](https://www.kaibanjs.com/share/vdZeou728T6bevU3BTNK)
:::
### The Challenge
Generating thoughtful and relevant comments for Reddit posts requires:
- **Content Analysis** to understand the post’s themes and arguments.
- **Engaging Responses** that resonate with the audience and encourage interaction.
- **Consistency and Quality** across multiple comments without sounding repetitive.
- **Scalability** for users managing multiple subreddits or accounts.
Manual comment creation is time-consuming and prone to inconsistencies, especially when working under tight deadlines or with high posting volumes.
### The Solution with KaibanJS
KaibanJS streamlines this process using AI agents that analyze posts, generate responses, and refine comments to ensure quality and engagement. This automated workflow reduces effort while maintaining authenticity and relevance.
### Traditional Approach Challenges
:::challenges
Manually responding to Reddit posts often involves:
1. **Post Analysis:** Reading and interpreting lengthy posts and comments.
2. **Drafting Responses:** Writing multiple variants that fit different tones or approaches.
3. **Review and Edits:** Refining responses for clarity, grammar, and alignment.
4. **Scalability Issues:** Repeating this process across multiple threads or communities.
KaibanJS solves these issues by automating each step through collaborative AI agents.
:::
### The Agentic Solution
KaibanJS employs a team of specialized AI agents, each focusing on a key part of the comment generation process to ensure accuracy and relevance.
:::agents
- **PostAnalyzer:**
- Role: Content Analyst.
- Goal: Analyze the content and comments to provide structured insights for comment generation.
- Responsibilities:
- Extracts core themes, arguments, and examples from the post.
- Identifies patterns in existing comments to enrich generated responses.
- Highlights gaps or angles to address in the comments.
- **CommentGenerator:**
- Role: Reddit Comment Creator.
- Goal: Generate engaging and context-aware comments.
- Responsibilities:
- Produces four distinct comment variants tailored to the post’s themes and examples.
- Ensures responses are natural, professional, and engaging.
- Balances insights, direct responses, and thoughtful questions.
- **CommentEvaluator:**
- Role: Comment Quality Assessor.
- Goal: Review and refine comments to ensure quality, relevance, and contextual alignment.
- Responsibilities:
- Evaluates clarity, tone, and alignment with the post’s context.
- Refines language and avoids repetitive structures.
- Formats comments in Markdown for seamless posting.
:::
### Input Information
To operate effectively, the following input data must be provided:
- **PostText:** The full text of the Reddit post to be analyzed.
- **ExistingComments:** A list of existing comments on the post to identify patterns and enrich the generated responses.
### Process Overview
Here’s how KaibanJS agents collaborate to generate and optimize Reddit comments:
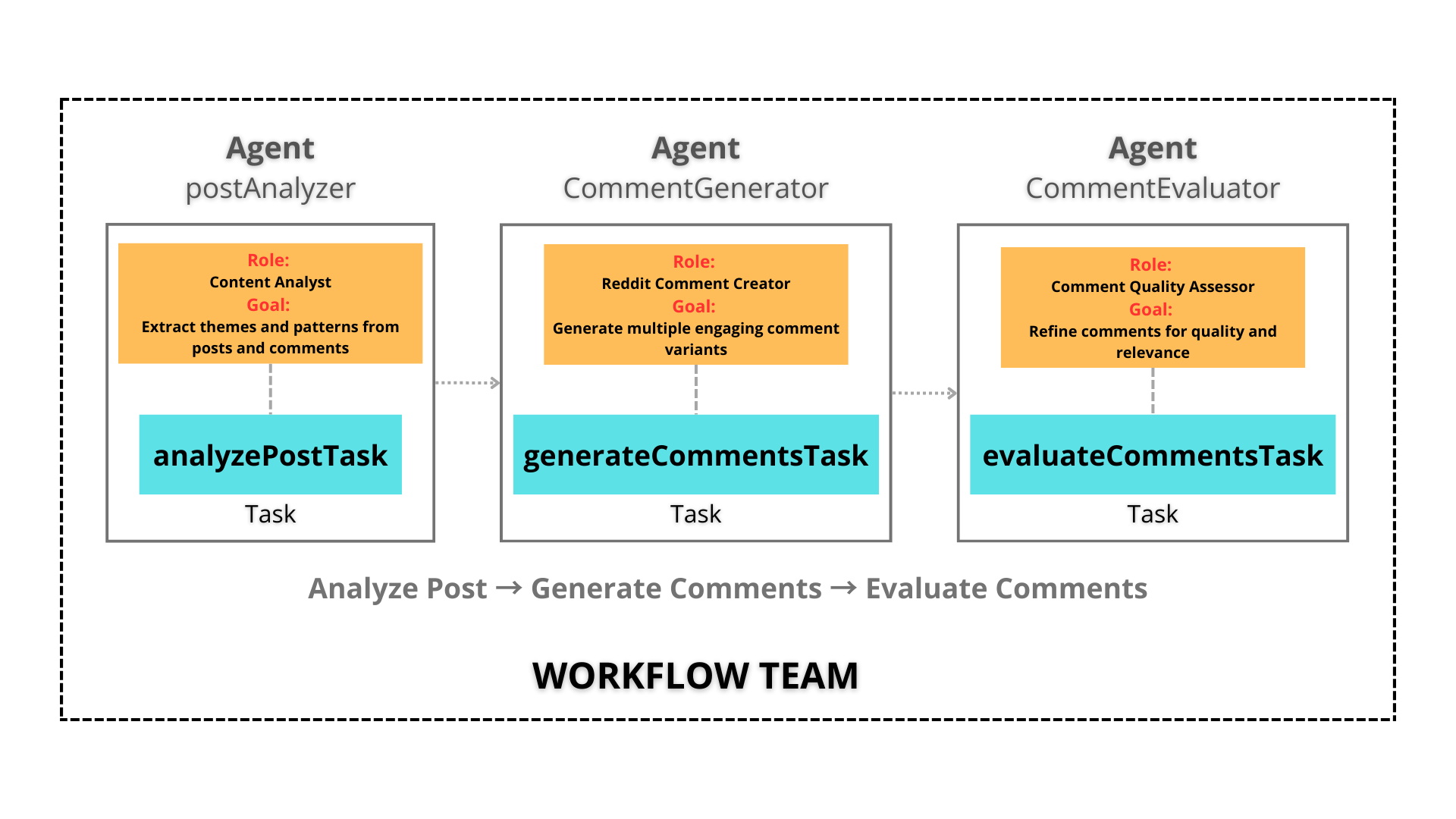
:::tasks
1. **Post Analysis:**
- The **PostAnalyzer** examines the post’s text and existing comments.
- Extracts themes, arguments, and recurring patterns to guide comment creation.
- Identifies discussion gaps or angles to enhance relevance.
2. **Comment Generation:**
- The **CommentGenerator** produces four unique and engaging comment variants.
- Ensures comments align with the post’s themes and tone.
- Includes reflective insights, direct responses, and thought-provoking questions.
3. **Evaluation and Refinement:**
- The **CommentEvaluator** reviews generated comments.
- Refines clarity, tone, and quality.
- Formats output in Markdown for posting readiness.
4. **Output Compilation:**
- Aggregates polished comments into Markdown format for easy deployment.
:::
### Outcome
The final outputs include:
- **Four comment options** optimized for different engagement styles.
- **Markdown formatting** for seamless posting on Reddit.
- **Balanced tone and relevance** to fit the community’s style and expectations.
### Expected Benefits
- **Efficiency:** Save hours by automating the analysis and comment creation process.
- **Consistency:** Maintain quality and tone across all comments.
- **Scalability:** Generate comments for multiple posts and threads effortlessly.
- **Quality Assurance:** Ensure comments are polished and contextually aligned.
### Get Started Today
Ready to simplify your Reddit comment generation? Explore KaibanJS and revolutionize the way you engage with online communities.
🌐 **Website**: https://www.kaibanjs.com/
💻 **GitHub Repository**: https://github.com/kaiban-ai/KaibanJS
🤝 **Discord Community**: https://kaibanjs.com/discord
---
:::info[We Value Your Feedback!]
Have suggestions or questions about this use case? Join our community or submit an issue on GitHub to help us improve. [Contribute Now](https://github.com/kaiban-ai/KaibanJS/issues)
:::